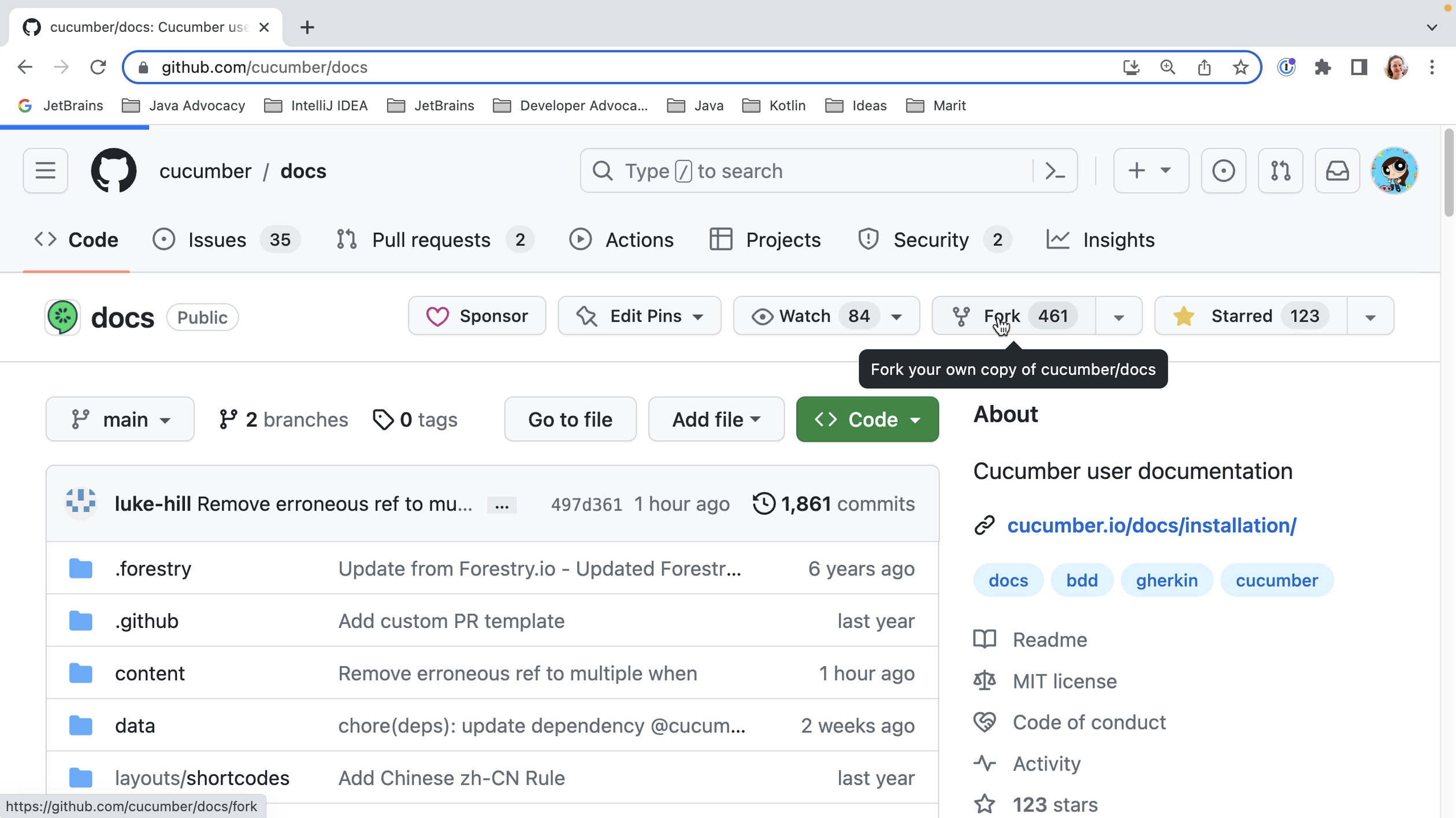
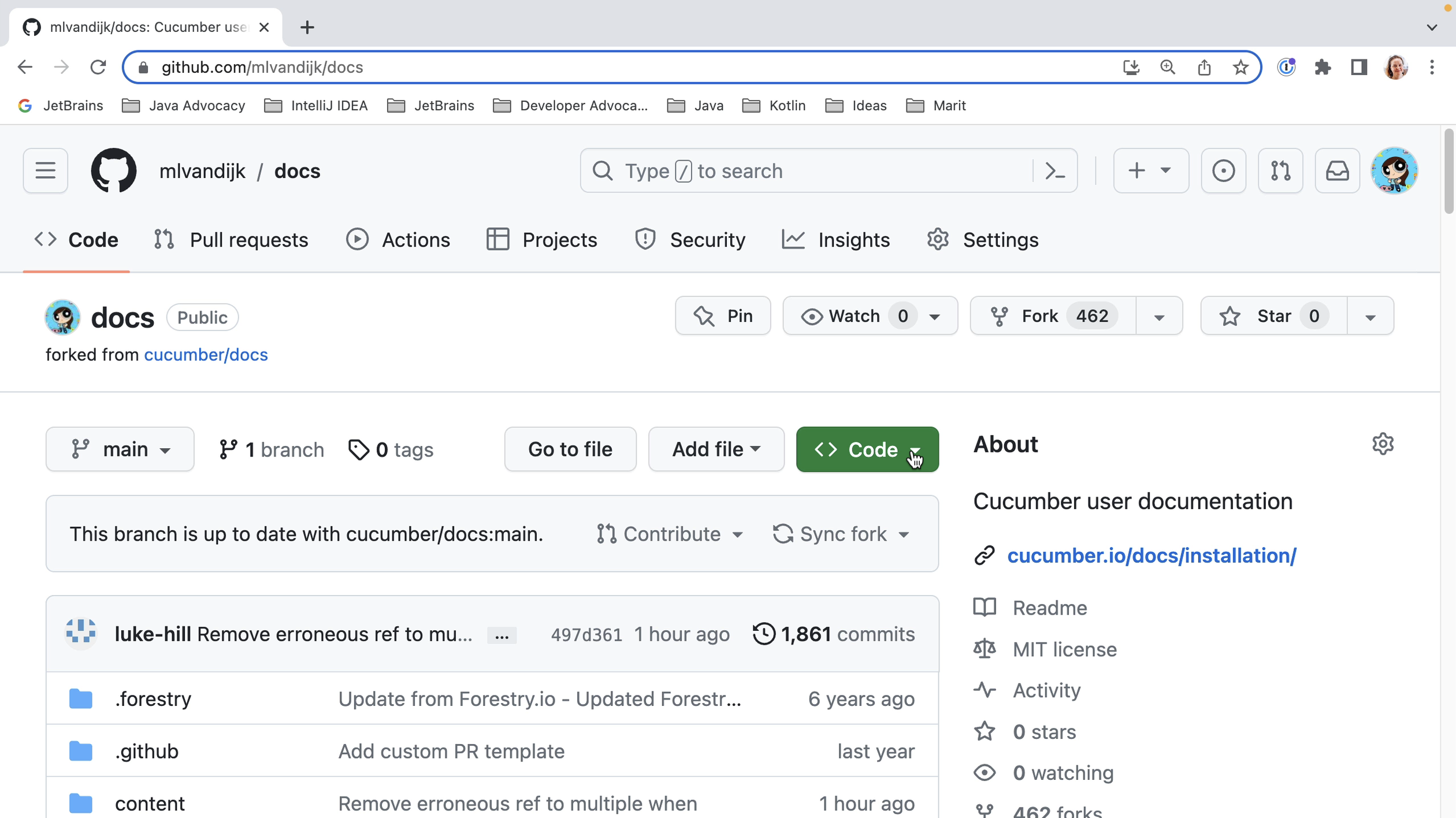
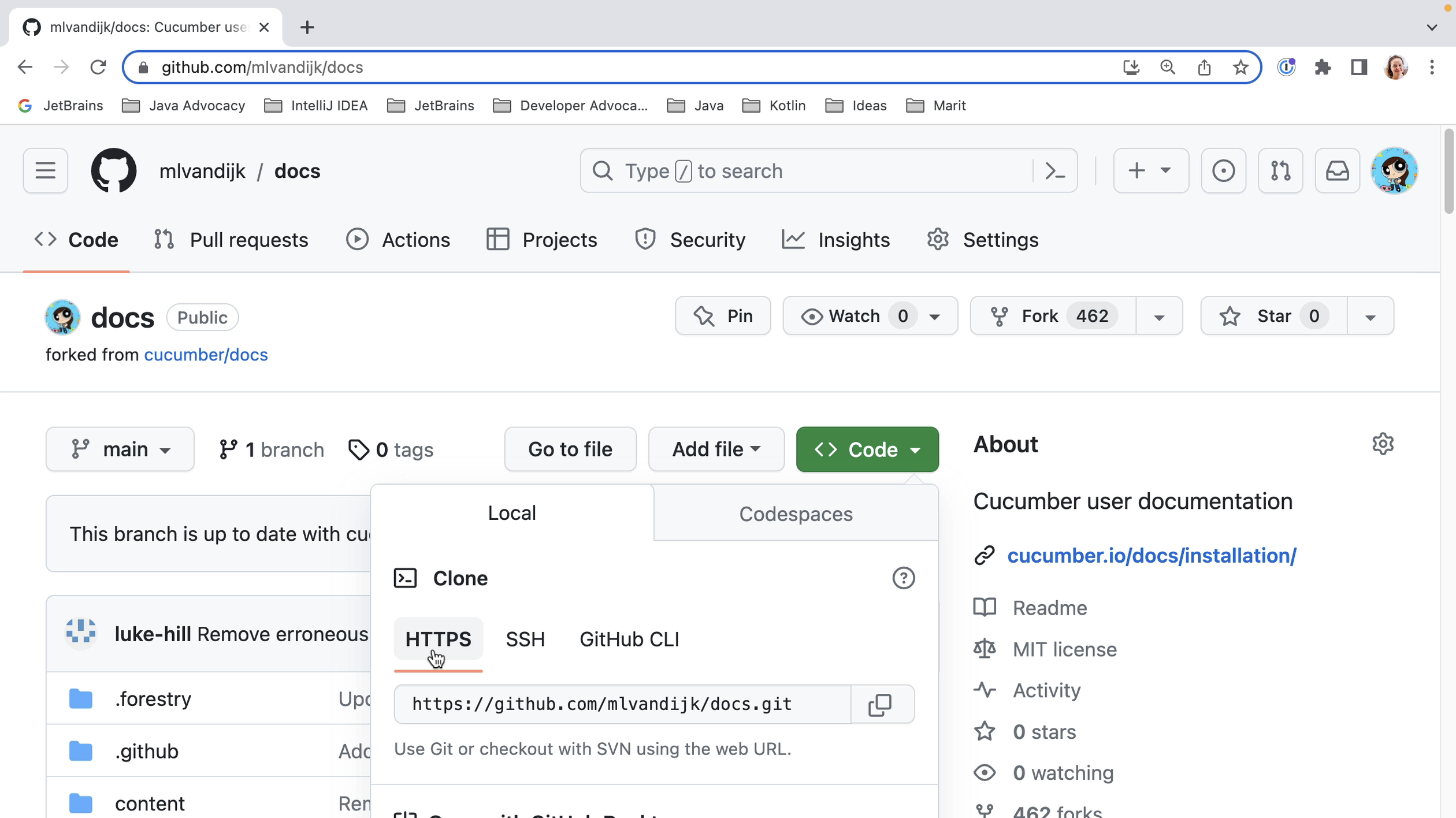
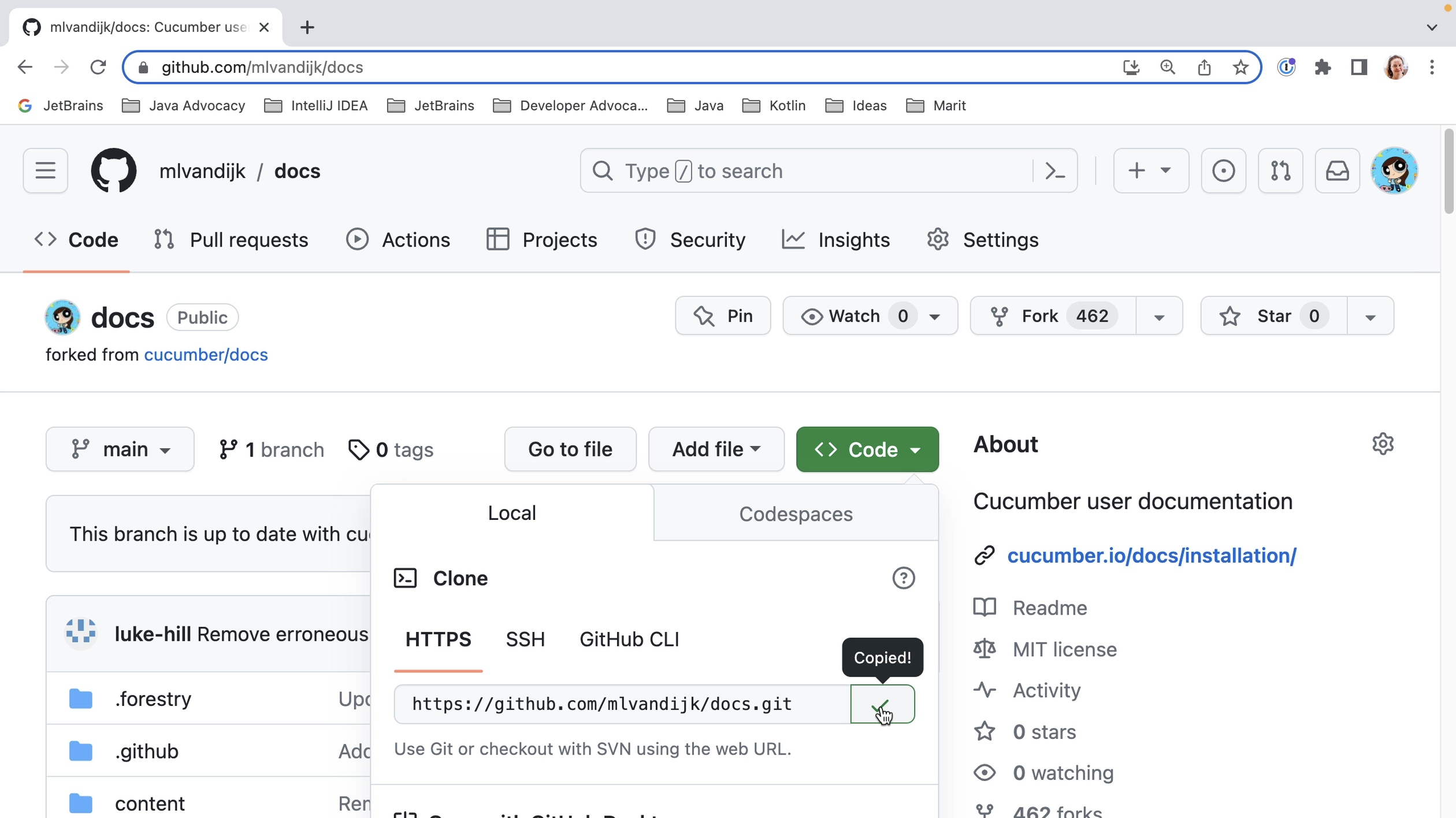
IntelliJ IDEA is designed to help developers like us stay in the flow while we’re working. Like all IDEs, it has a lot of functionality available, but it’s designed to get out of your way to let you focus on the code.
Take a look at this overview of IntelliJ IDEA.
Introduction
- Find Action: ⌘ ⇧ A (on macOS) / Ctrl+Shift+A (on Windows/Linux)
- Feature Trainer
- Hide all windows: ⌘ ⇧ F12 (on macOS) / Shift+Command+F12 (on Windows/Linux)
- Project tool window: ⌘1 (on macOS) / Alt+1 (on Windows/Linux)
- Quick Switch Scheme: ^`(on macOS) / Ctrl+` (on Windows/Linux)
- IDE viewing modes
- Preferences: ⌘, (on macOS) / Ctrl+Alt+S (on Windows/Linux)
Coding assistance
- Code completion
- Complete Current Statement: ⌘ ⇧ ⏎ (on macOS) / Shift+Ctrl+Enter (on Windows/Linux)
- Show Context Actions: ⌥ ⏎ (on macOS) / Alt+Enter (on Windows/Linux)
- Intention actions
- Navigate to next highlighted error: F2
- Navigate to previous highlighted error: Shift F2
- Generate code: ⌘ N (on macOS) / Alt + Insert (on Windows/Linux)
- Live templates
Refactoring
- Rename: Shift F6
- Extend selection: ⌥ Up (on macOS) / Ctrl+W (on Windows/Linux)
- Extract variable: ⌘ ⌥ V on macOS) / Ctrl+Alt+V (on Windows/Linux)
- Postfix completion
- Reformat code: ⌘ ⌥ L (on macOS) / Ctrl+Alt+L (on Windows/Linux)
- Move statement up: ⇧⌘ Up (on macOS) / Ctrl+Shift+Up (on Windows/Linux)
- Surround with: ⌘ ⌥ T (on macOS) / Ctrl+Alt+T (on Windows/Linux)
- SmartType Completion: ^ ⇧ Space (on macOS) / Shift+Ctrl+Space (on Windows/Linux)
- Inline: ⌘ ⌥ N (on macOS) / Ctrl+Alt+N (on Windows/Linux)
- Extract method: ⌘ ⌥ M on macOS) / Ctrl+Alt+M (on Windows/Linux)
Testing & Debugging
- Navigate to Test: ⌘ ⇧ T (on macOS) / Ctrl+Shift+T (on Windows/Linux)
- Run test: ^ R (on macOS) / Shift+Ctrl+F10 (on Windows/Linux)
- Run tests: ^ ⇧ R (on macOS) / Shift+Ctrl+F10 (on Windows/Linux)
- Stretch to Top: ^ ⌥ Up (macOS) / Ctrl+Alt+Shift+Up (Windows/Linux)
- Stretch to Bottom: ^ ⌥ Down (macOS) / Ctrl+Alt+Shift+Down (Windows/Linux)
- Toggle breakpoint: ⌘ F8 (macOS) / Ctrl+F8 (Windows/Linux)
- Debug test: ^D (macOS) / Shift+F9 (Windows/Linux)
- Debug code
- Step Into: F7
- Step Over: F8
- Evaluate expression: ⌥ F8 (macOS) / Alt+F8 (Windows/Linux)
- Resume Program: ⌥ ⌘ R (macOS) / F9 (Windows/Linux)
- Run anything: ^ ^ (macOS) / Ctrl Ctrl (Windows/Linux)
- (video) Debugger basics in IntelliJ IDEA (Mala Gupta)
- (video) Advanced Debugger Features in IntelliJ IDEA (Mala Gupta)
- (video) IntelliJ IDEA Pro Tips: Debugging Java Streams
Navigation
- Navigate backwards: ⌘ [ (on macOS) / Ctrl+Alt+Left (on Windows/Linux)
- Navigate forwards: ⌘ ] (on macOS) / Ctrl+Alt+Right (on Windows/Linux)
- Find usages / declaration: ⌘ B (on macOS) / Ctrl+B (on Windows/Linux)
- Recent Files: ⌘E (on macOS) / Ctrl+E (on Windows/Linux)
- Recent locations: ⇧⌘E (on macOS) / Ctrl+Shift+E (on Windows/Linux)
- Search everywhere: ⇧⇧ (on macOS) / Shift Shift (on Windows/Linux)
- Find in files: ⇧⌘F (on macOS) / Ctrl+Shift+F (on Windows/Linux)
Reading Code
- Folding -> Expand: ⌘ + (on macOS) / Ctrl+ + (on Windows/Linux)
- Folding -> Collapse: ⌘ – (on macOS) / Ctrl+ – (on Windows/Linux)
- Folding -> Expand All : ⇧ ⌘ + (on macOS) / Ctrl+Shift+ + (on Windows/Linux)
- Folding -> Collapse All: ⇧ ⌘ + (on macOS) / Ctrl+Shift+ – (on Windows/Linux)
- File Structure: ⌘ F12 (macOS) / Ctrl+F12 (Windows/Linux) – Twice to expand list
- Quick documentation: F1 (macOS) / Ctrl+Q (Windows/Linux)
- Toggle Rendered View: ^ ⌥ Q (macOS) / Ctrl+Alt+Q (Windows/Linux)
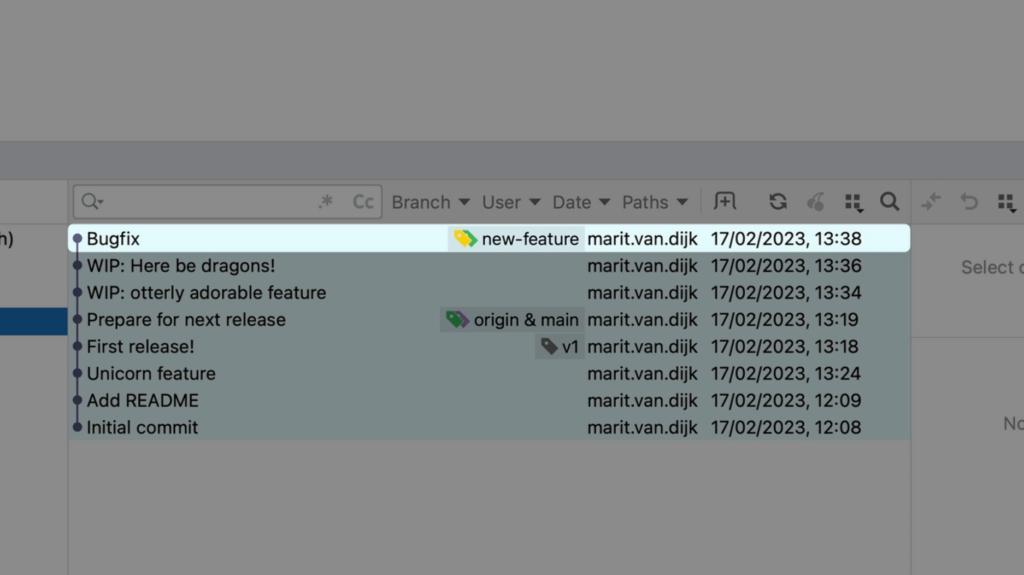
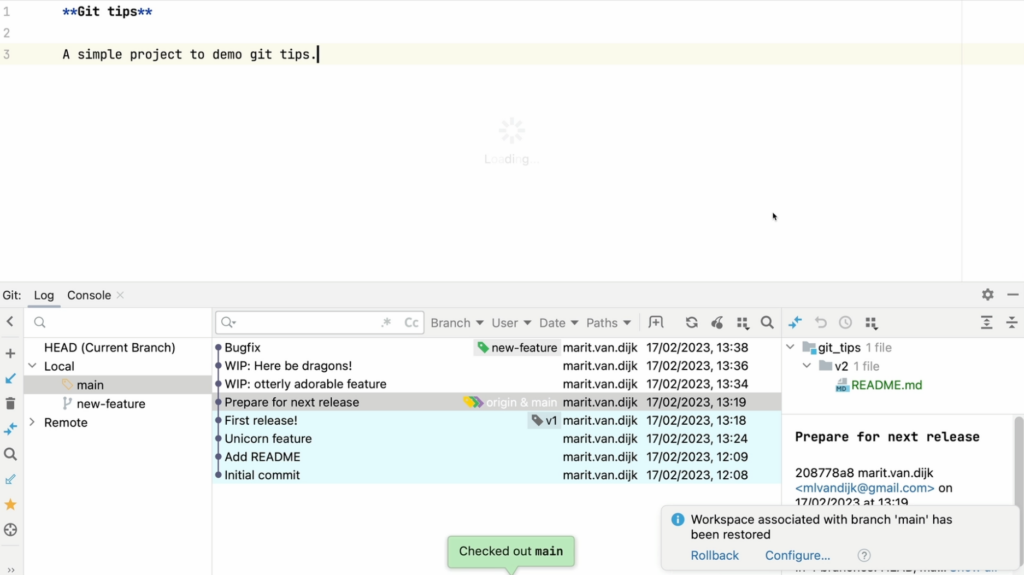
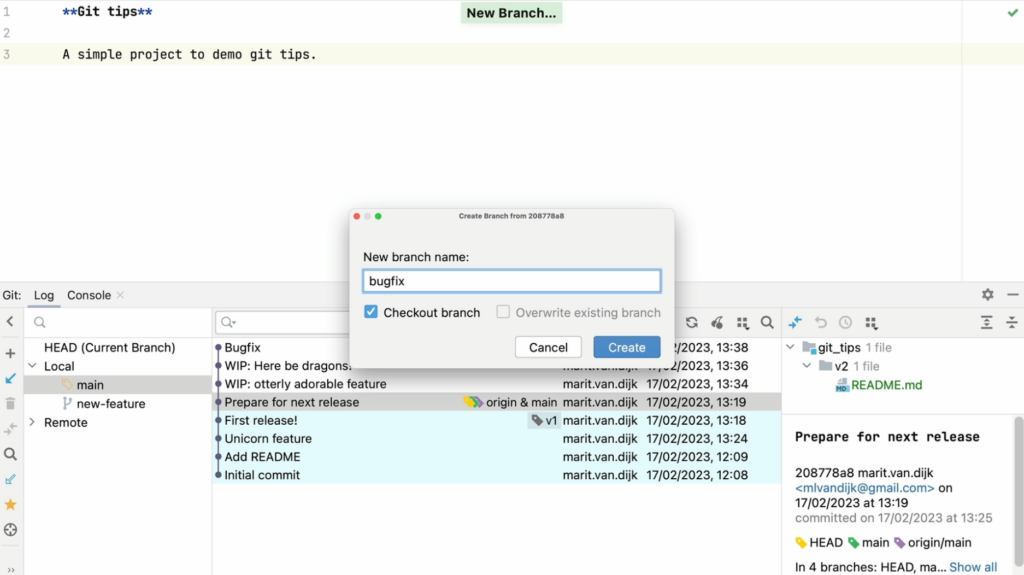
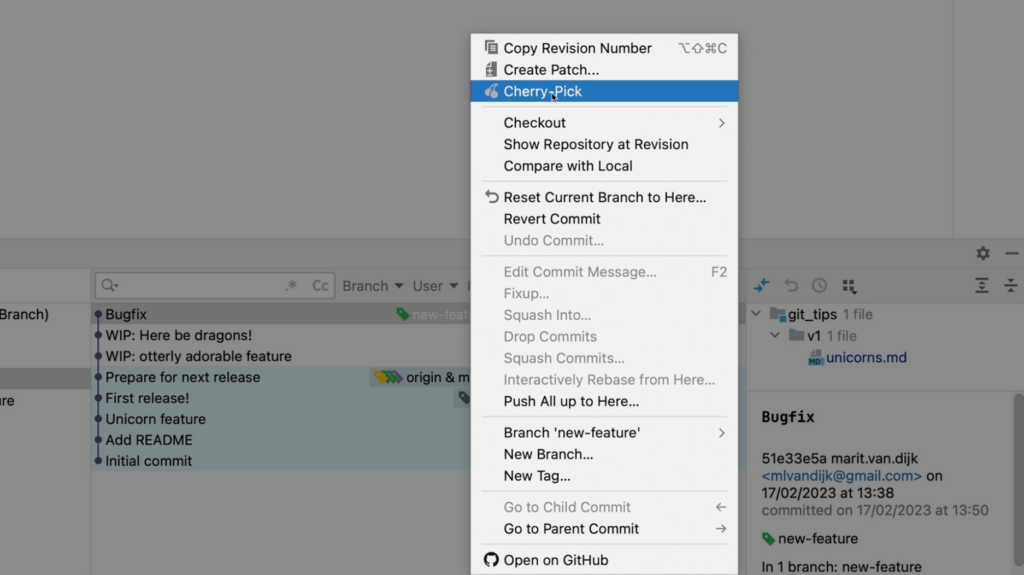
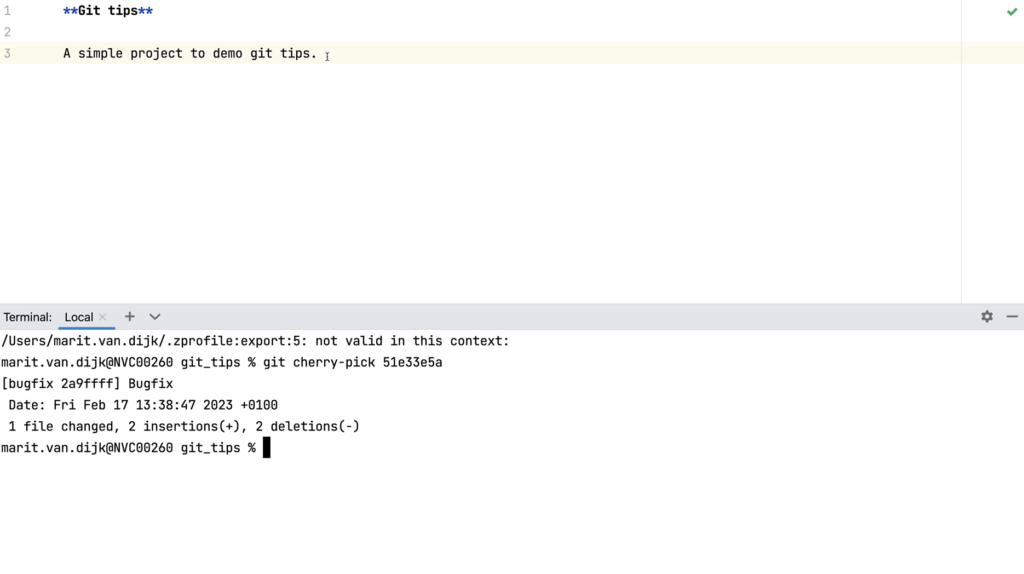
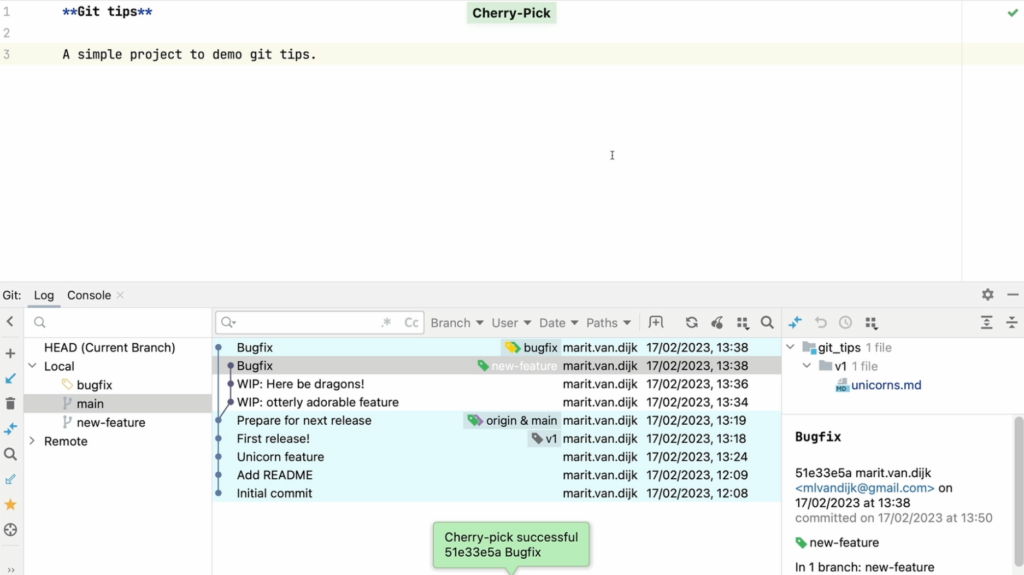
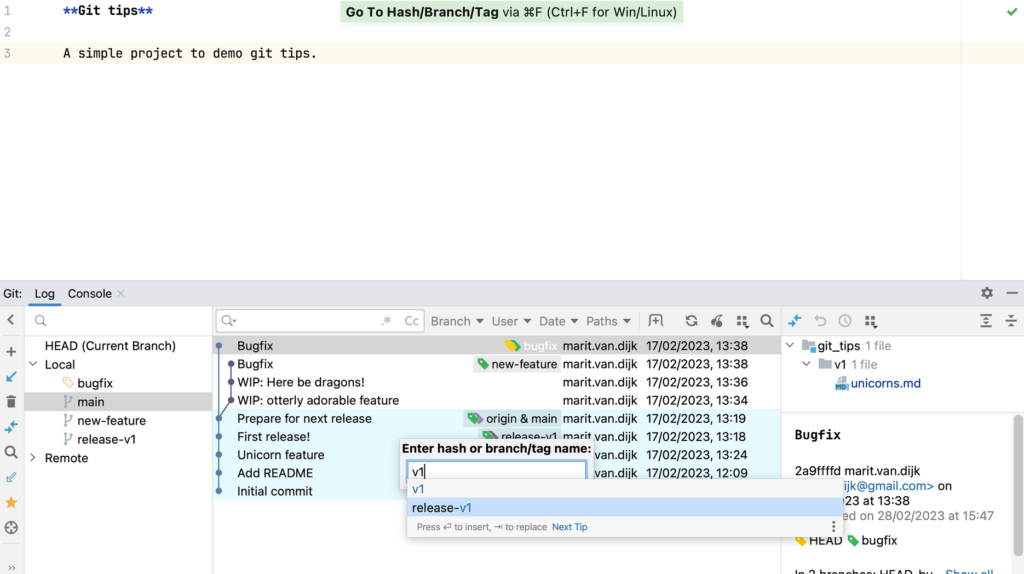
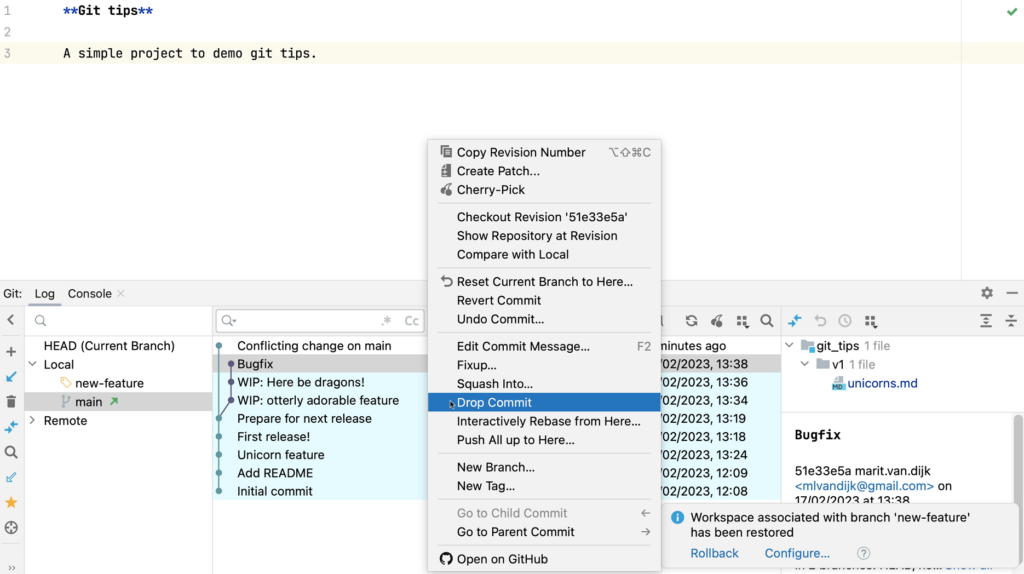
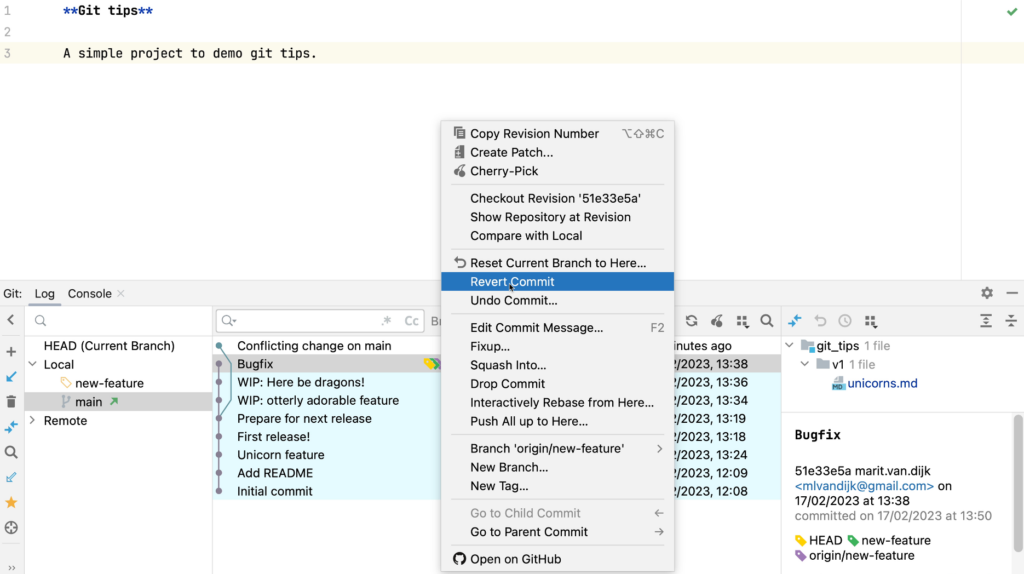
Version Control support (Git)
- Commit: ⌘ 0 (macOS) / Alt+0 (Windows/Linux)
- Jump to last tool window: F12
- Show diff: ⌘ D (macOS) / Ctrl+D (Windows/Linux)
- Commit Anyway and Push: ⌥ ⌘ K (on macOS) / Ctrl+Alt+K (on Windows/Linux)
- Git tool window: ⌘9 (on macOS) / Alt+9 (on Windows/Linux)
- Terminal: ⌥ F12 (on macOS) / Alt+F12 (on Windows/Linux)
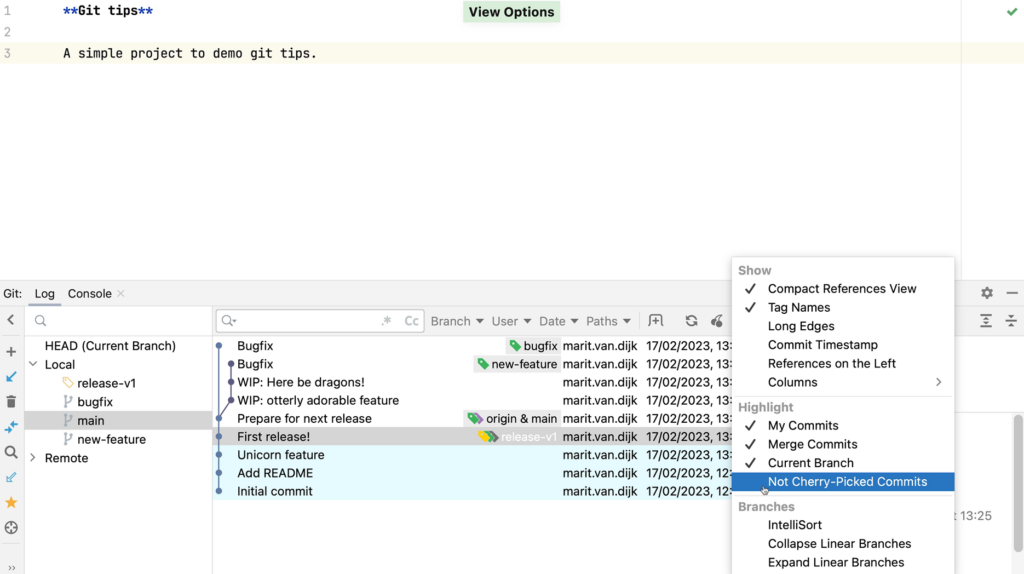
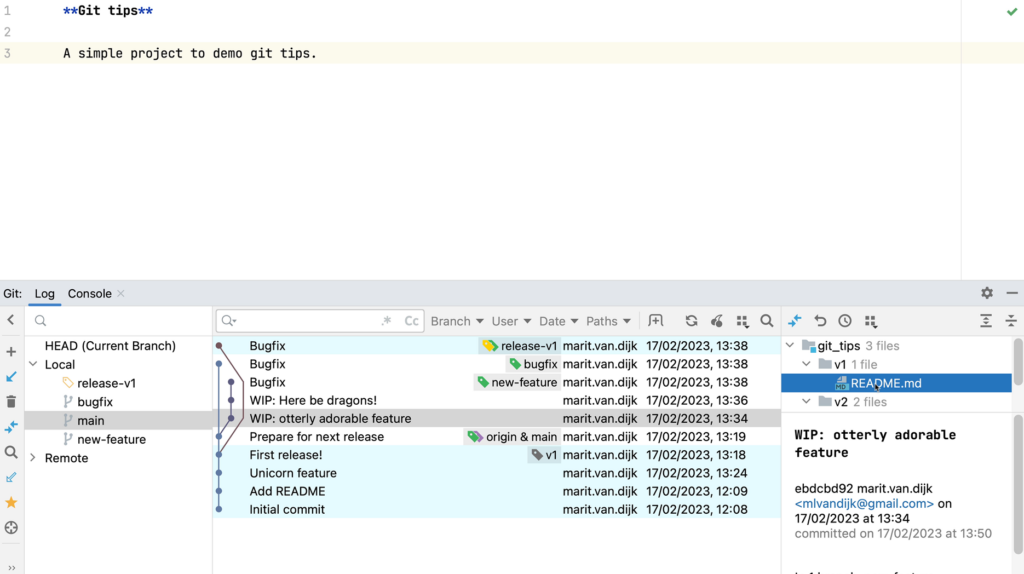
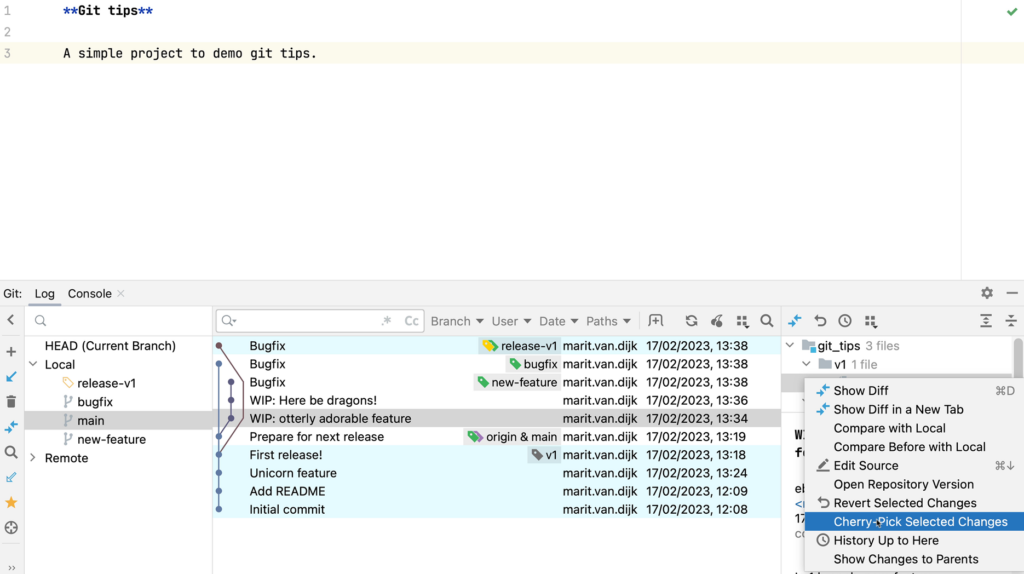
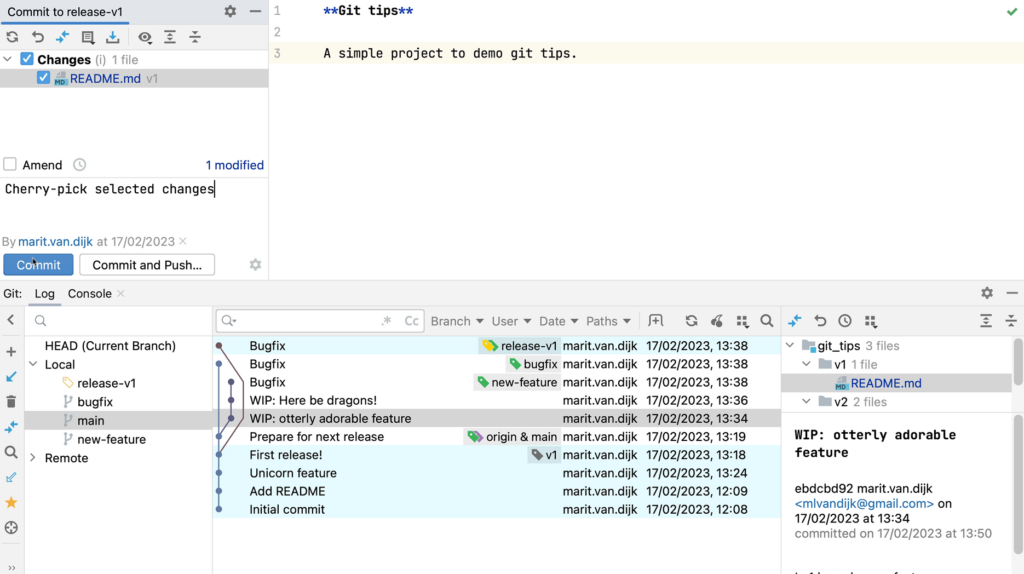
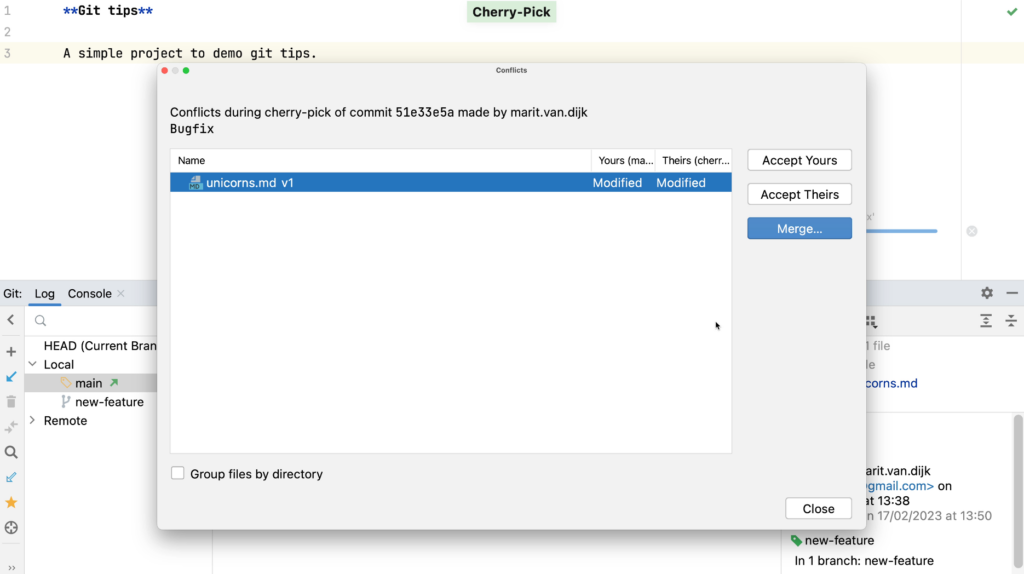
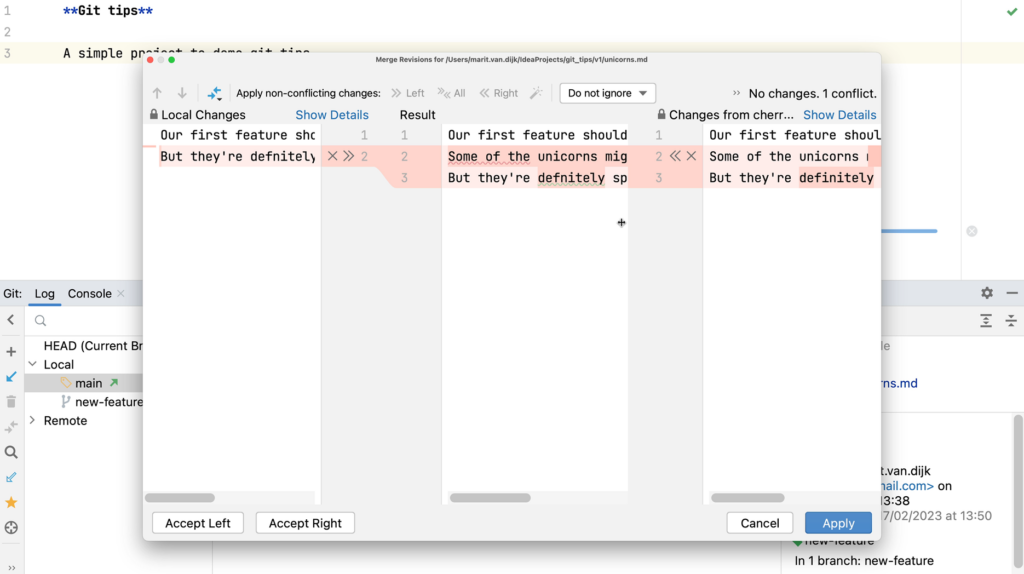
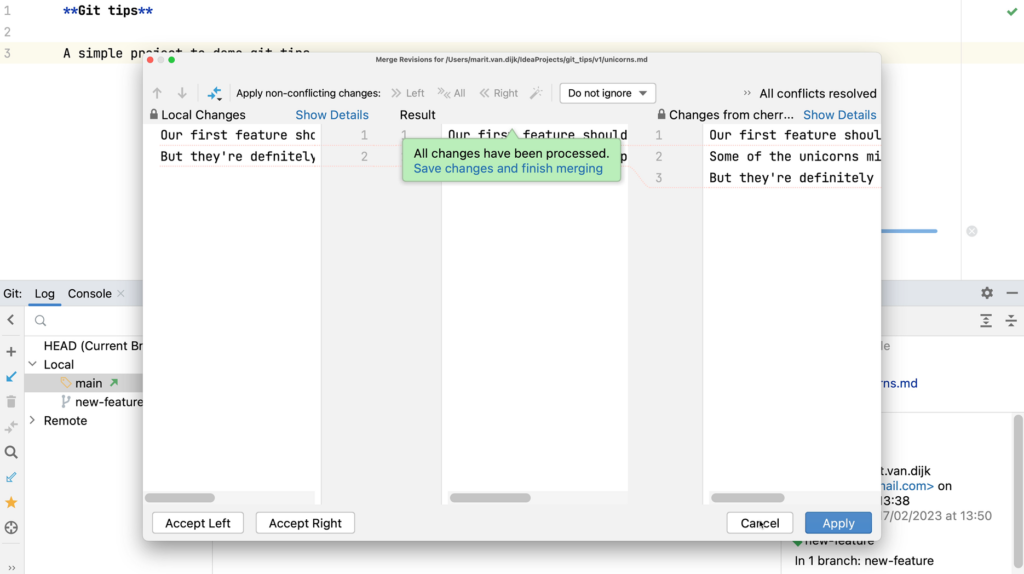
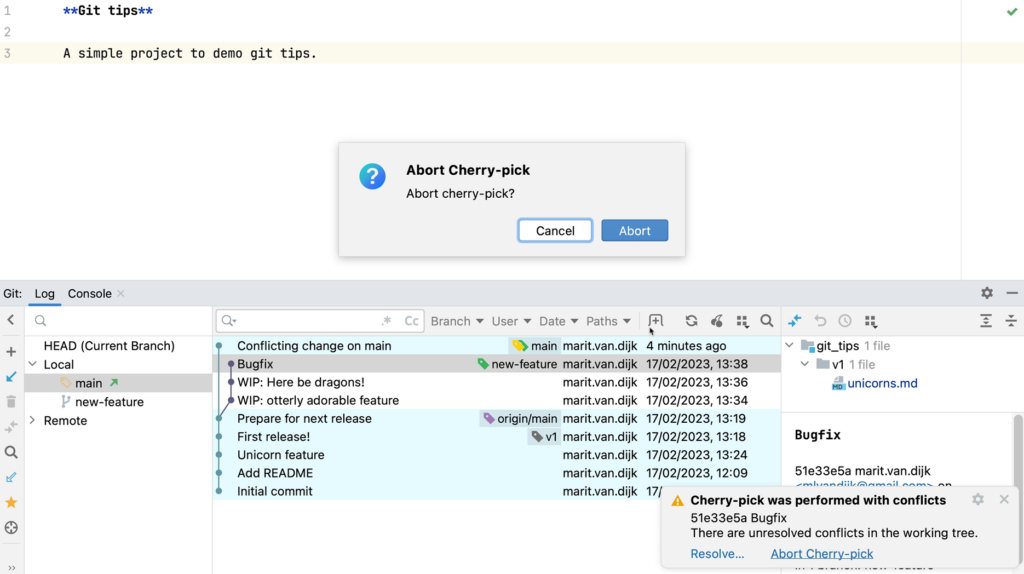
- Git integration
Language and technology support
- JVM Languages: Java, Kotlin, Groovy and Scala
- JVM Frameworks: Spring, Quarkus, Micronaut, Jakarta EE and more
- Non-JVM Technologies: JavaScript, TypeScript, HTML and more
- Navigate to file: ⌘ ⇧ O (on macOS) / Shift+Ctrl+N (on Windows/Linux)
- Convert to Kotlin: ⌥⇧⌘K (on macOS) / Ctrl+Alt+Shift+K (on Windows/Linux)
- Preview file in: ⌥F2 (on macOS) / Alt+F2 (on Windows/Linux)
- Language injections
- (video) IntelliJ IDEA Pro Tips: Inject Language or Reference
Integrated tools support
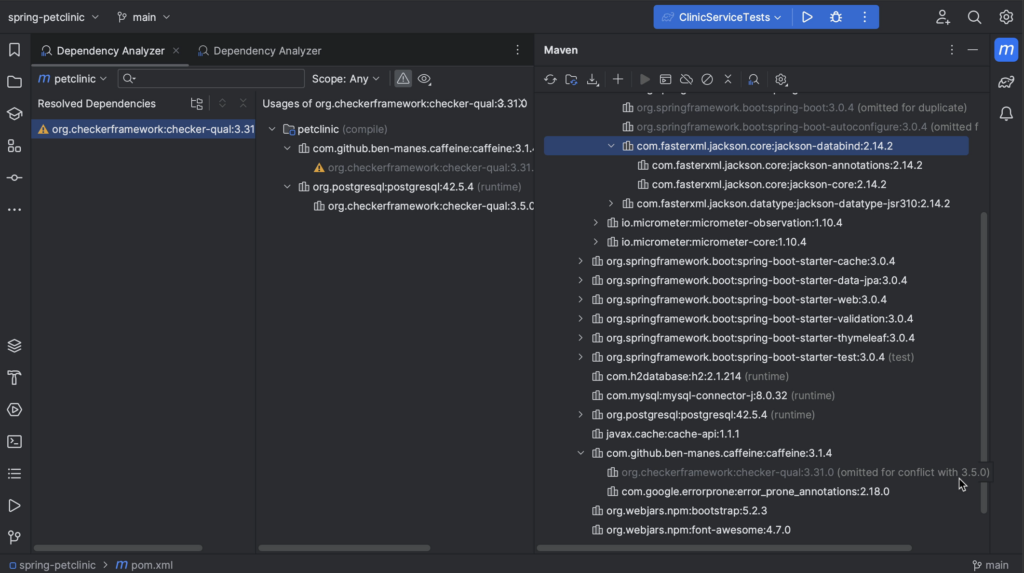
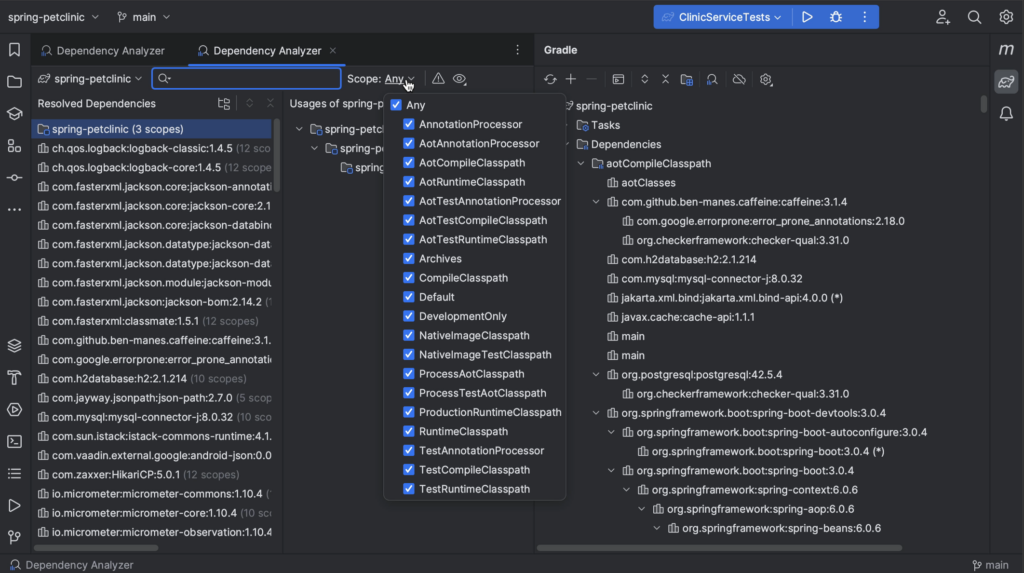
- Build tools: Maven, Gradle and more
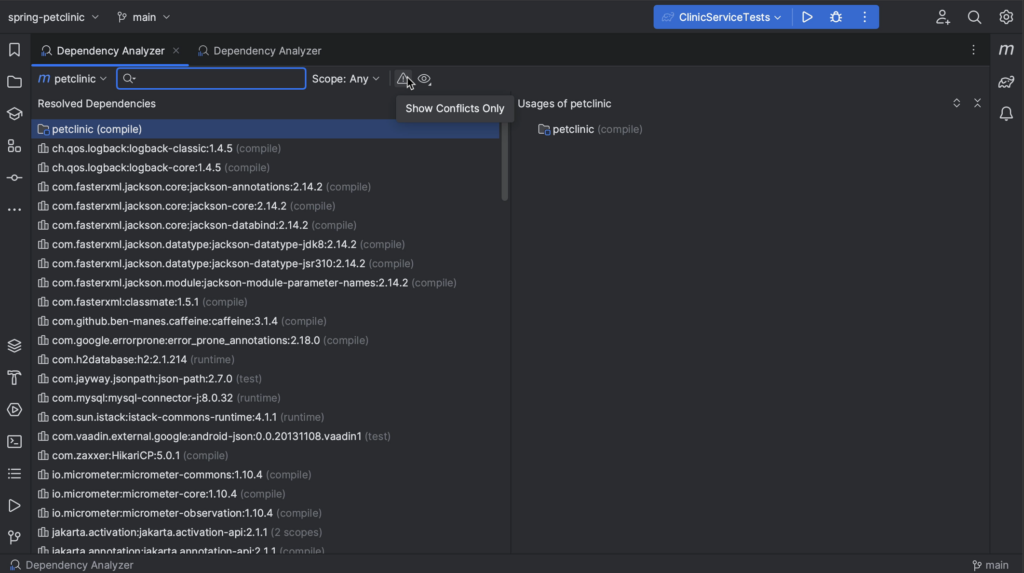
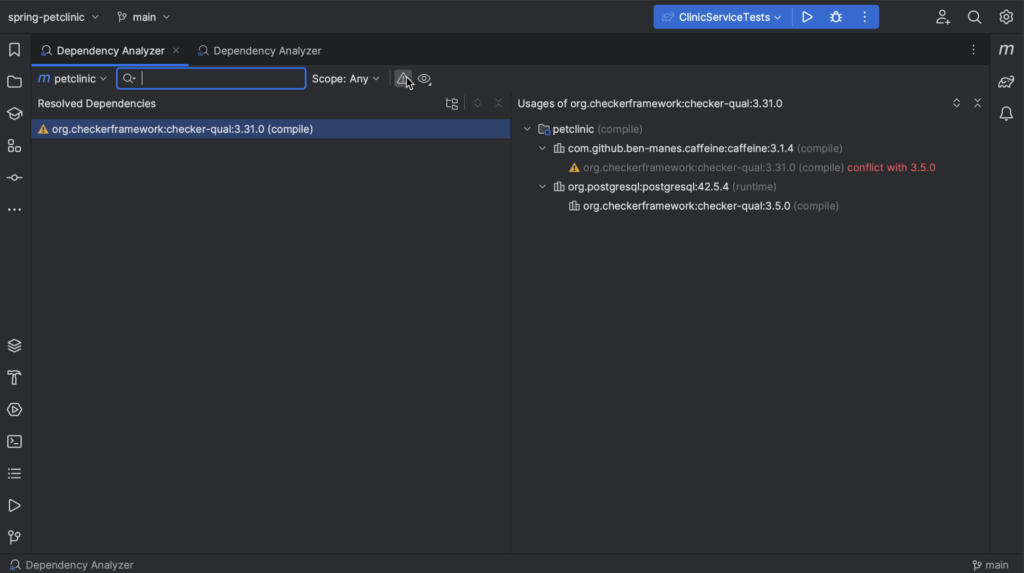
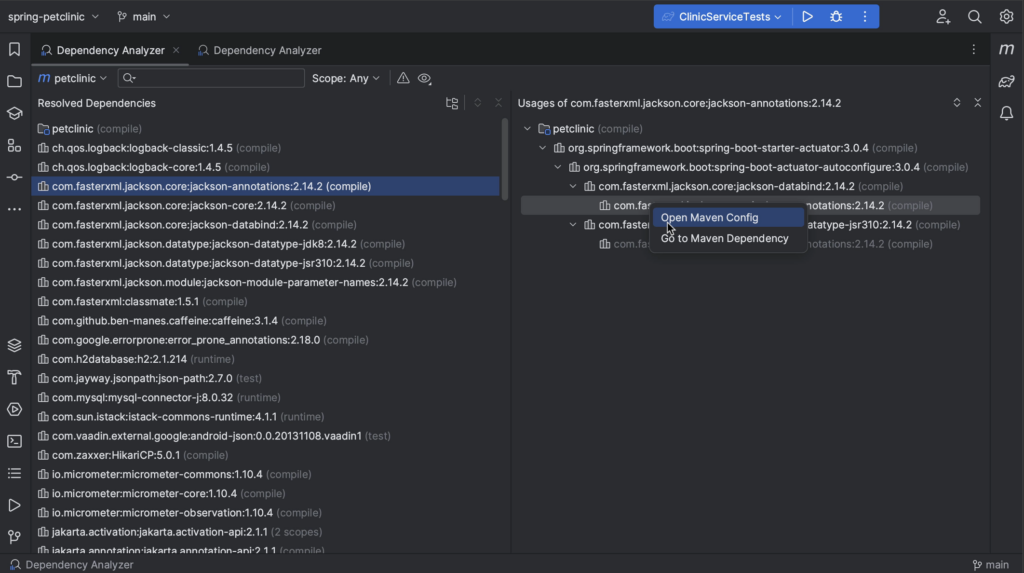
- Managing dependencies: Package Search, Package analysis
- Services tool window
- Docker
- Profiling
- (video) Profiling Tools and IntelliJ IDEA Ultimate
- Code With Me
- Remote Development
- JetBrains Gateway