Discover 7 powerful ways to supercharge your version control with JetBrains AI Assistant!
From resolving tricky merge conflicts to generating precise commit messages, AI Assistant offers tools that can save you time and boost your productivity. Learn how to ask questions about your project’s version control history, review local changes, and even customize commit prompts to fit your style. Whether you’re dealing with complex git commands or want help revisiting old commits, JetBrains AI Assistant has you covered.
Watch now to explore how you can transform your version control experience!
Struggling to understand complex code? JetBrains AI Assistant is here to help!
In this video, we walk you through practical examples of how the AI Assistant simplifies code comprehension. From summarizing projects and explaining classes to clarifying regex and runtime errors, this tool enhances your productivity and understanding. You’ll also learn how to use natural language queries, write concise documentation, and even dig into commit history with ease.
Whether you’re dealing with unfamiliar code or just need quick insights, JetBrains AI Assistant has you covered!
As developers, we spend more time reading code than writing it, and this video provides tips to enhance your code-reading skills within the IntelliJ IDEA IDE. Learn how to leverage features like syntax highlighting, inlay hints, and code formatting to navigate and understand code effortlessly. Discover techniques to quickly scan code, collapse and expand sections for efficient navigation, and use powerful search functionalities to locate specific elements.
Whether you’re a beginner or an experienced developer, these tips will empower you to read and comprehend code with confidence, making your coding journey in IntelliJ IDEA a seamless and productive experience.
While working on a new feature, you find some small other things to fix. Since these changes are unrelated, you probably shouldn’t commit them together. You could revert these changes to redo them separately, but who wants to do extra work? Fortunately, you can now select which chunks or even lines of changes to add to your commit. You can commit the rest separately or even move it to a new change list.
When working with large, complex software projects, we need to understand the dependencies between components in your projects.
IntelliJ IDEA’s Dependency Structure Matrix (DSM), or Dependency Matrix, that can help us with this! Let’s take a look at how to use the Dependency Structure Matrix to see dependencies between different components, like modules, packages, and classes. See how to identify dependencies, find cyclic or mutual dependencies, and visualize the flow of dependencies to see which components use or depend on other components and vice versa.
IntelliJ IDEA is designed to help developers like us stay in the flow while we’re working. Like all IDEs, it has a lot of functionality available, but it’s designed to get out of your way to let you focus on the code.
Take a look at this overview of IntelliJ IDEA.
Introduction
Find Action: ⌘ ⇧ A (on macOS) / Ctrl+Shift+A (on Windows/Linux)
On June 23, 2023 Hanno Embregts and I performed a lightning talk / pop music quiz called “public static void main 🎶 “. This was based on a Tweet that said “I realized that you can sing “public static void main” like “Everybody dance now” and I can’t stop doing it”. Hanno found 15(!!) songs that would also work, and we created a pop music quiz.
On June 23, 2023 Hanno Embregts and I performed a lightning talk / pop music quiz called “public static void main 🎶 “.
A few weeks later, I saw a tweet that said “I realized that you can sing “public static void main” like “Everybody dance now” and I can’t stop doing it”. (And, I’ve been doing just that ever since.) Someone responded to my retweet by pointing out that this also works for Vamos a la playa.
I realised that you can sing "public static void main" like "Everybody dance now" and I can't stop doing it
So I pitched the idea to Hanno of doing a “pop music quiz” with different songs where we would replace the lyrics with “public static void main” and we could have the audience guess what the original song was. A few months later, Hanno contacted me to say he had found at least 15(!!) songs where this would work. Apparently, he had gone through the Top 2000 looking for songs he thought might work. So we got together to discuss this idea, write an abstract and figure out where to submit it too. We submitted to several conferences that offered lightning talks slots and … got accepted to Joy of Coding 2023! Coincidentally, this is also where I got started speaking, so I was very excited to return.
— Marit van Dijk ☕️🥑 (@MaritvanDijk77) June 23, 2023
Time constraints
Unfortunately, we had to cut some songs due to the 5-minute limit, so we selected the 6 we thought would work best. We selected a quiz tool, created the questions, and some videos to go with them using IntelliJ IDEA‘s live templates. The Joy of Coding organizers were extremely helpful in allowing us to take the last slot in the lightning talk line-up, letting us use our own laptop to run the quiz, and talking to the venue to get Hanno an audio monitor at the last minute.
Joy of Coding 2023
On the day of the conference, we had a lot of fun playing and singing along.
And to our surprise, we ended up with a tie for first place! Fortunately, we had some back-up songs we could use to settle this tie in a kind of “sudden death” match between the two top contestants.
Many thanks to original tweeters for the idea (I’ll forgive you for also getting the song stuck in my head), Hanno Embregts for the awesome collaboration, Yosuf Haydary for pictures and videos of the event and Joy of Coding for having us!
If you’re working on a real world project, you’re probably using external dependencies. You might need to analyze which dependencies your application uses. For example, you may want to find out how a particular version of a dependency ended up in your application. Let’s take a look at how IntelliJ IDEA can help you to analyze dependencies.
Any real world Java project will likely use external dependencies. As we’ve seen over the last few years, it’s important to keep these dependencies up to date. We used to have to manually check for updates, but fortunately these days there are tools available that can help us with this. Because, let’s be honest, most developers don’t enjoy maintaining applications. We’d much rather be using cool new tools and/or language features, and solving interesting problems. Sorry, I mean: delivering business value! But we are responsible for keeping our dependencies up to date, so let’s make that as easy as possible. In this blog post we will look at one category of tools that can help us: bots that can automatically create pull requests (PRs) to keep dependencies secure and up to date.
For Java, we currently have three options: Dependabot, Renovate and Snyk Open Source. They each support other programming languages too, but as I mostly use Java and other JVM languages I have limited myself to these. Let’s take a look at which features they provide and their similarities and differences.
Sidenote: In order to try out and compare these bots, I’ve added them one by one to my personal GitHub profile and will describe here how to add them to your GitHub profile, as well as link to information about other integration options.
Dependabot
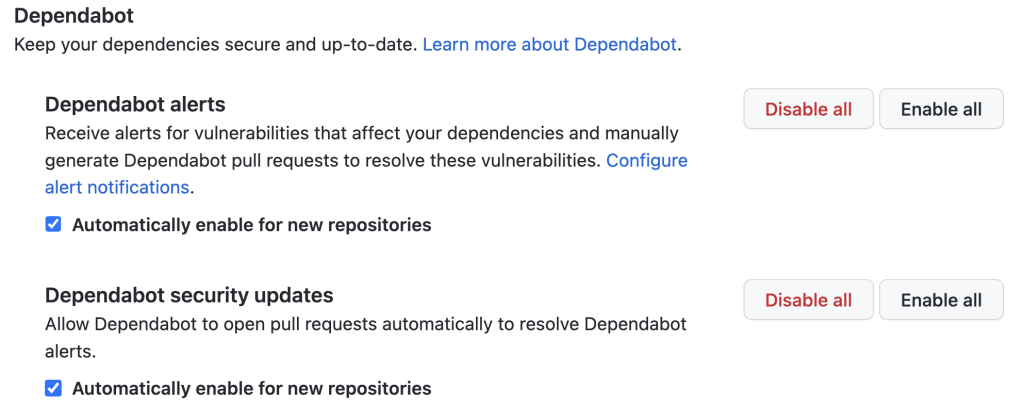
The first bot we will look at is Dependabot. Since Dependabot is GitHub native, we can enable most of its features from the Settings > Security > Code security and analysis. Here we can enable (or disable) the available features, and select which ones we would like to automatically enable for new repositories.
Dependabot settings on GitHub
Features
Dependabot offers the following features: Alerts, security updates and vulnerability updates.
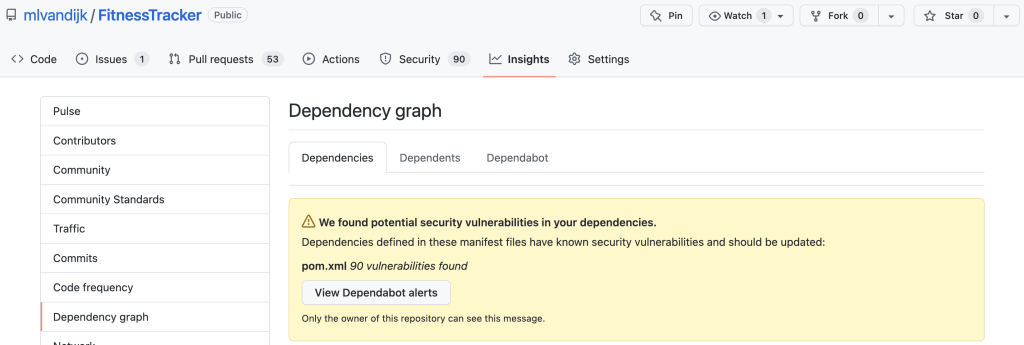
When Dependabot is enabled, it provides a Dependency Graph under the Insights tab of your project. The Dependencies tab shows any alerts to the owner of the repository. The Dependents tab shows any projects that depend on your project. In the Dependabot tab version updates can be configured.
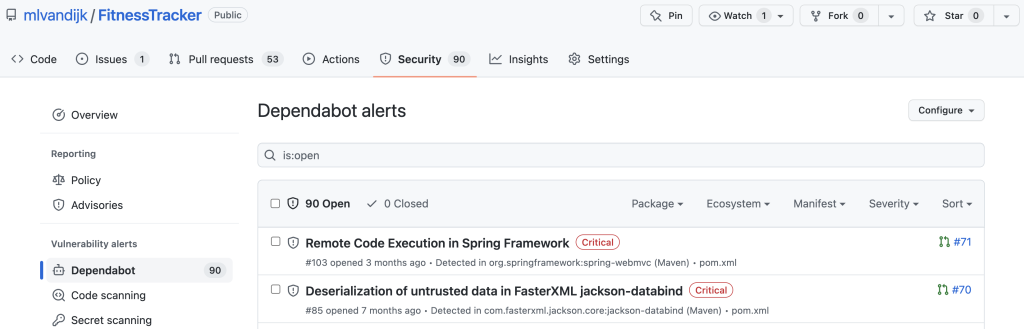
When we enable Dependabot alerts, we will receive alerts for vulnerabilities in our repositories and we can manually generate pull requests (PRs) to resolve them. We can configure how we would like to receive these alerts. We can also view them in the Dependency Graph in the Dependencies tab.
Dependabot Dependencies graph
We can click the button to View Dependabot alerts to see more information about the alerts.
Dependabot alerts
Pull requests
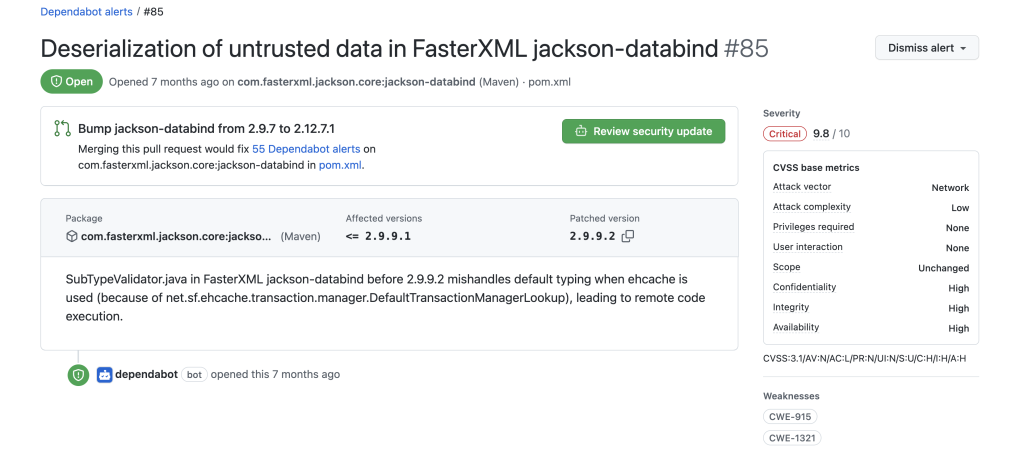
When we enable Dependabot security updates, Dependabot will open pull requests (PRs) automatically to resolve vulnerabilities. These PRs provide information about the severity of the vulnerability, CVSS base metrics, and CVEs. We can hover over the CVSS base metrics and CVEs to get more information. We can review the changes, or dismiss the alert.
Dependabot security update
To enable version updates, you need to add a dependabot.yml file to your repository.
Configuration
In this configuration file, you need to provide the package manager, the directory that contains your manifest file and a scheduling interval (daily, weekly, or monthly). You can configure more options, like when it should be scheduled (date, time, timezone), the maximum number of PRs (the default is 5), rebase strategy, settings that can help you manage the PRs like target branch, assignees, reviewers, commit messages and labels, and more. For more information on configuration options, see the Dependabot documentation on configuration.
Like Dependabot, Renovate offers security updates and version updates. In addition, Renovate will also create a project dashboard listing all updates needed on a particular project.
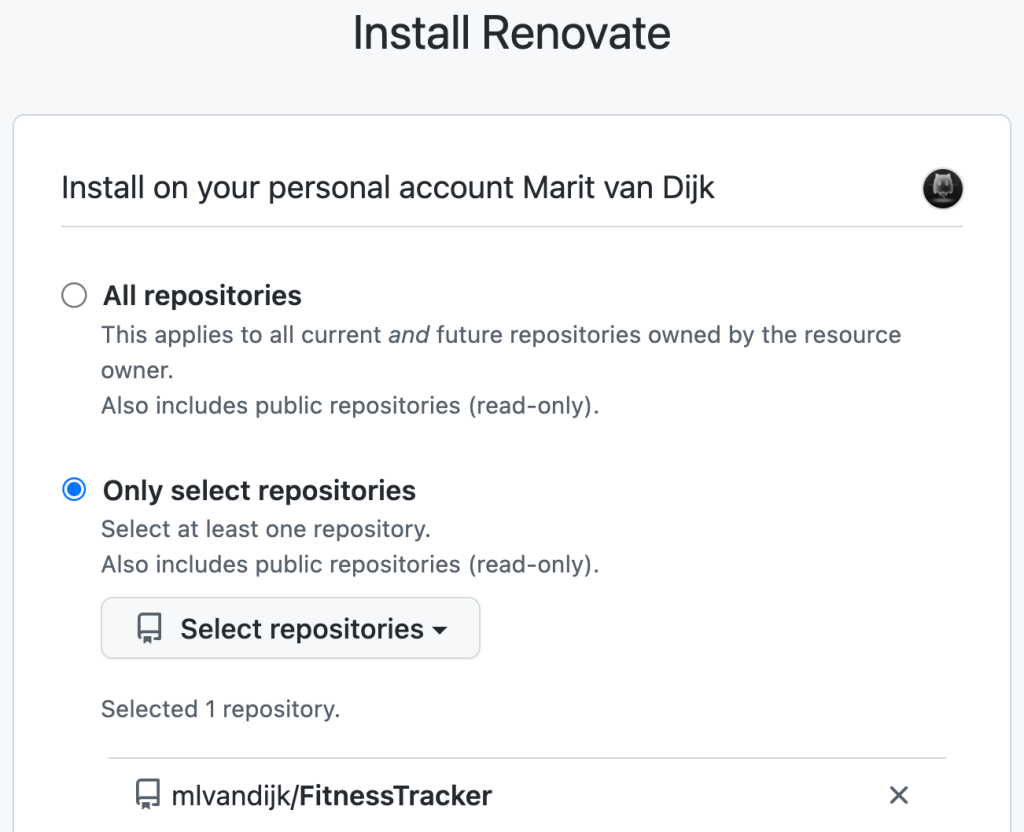
Renovate is available on GitHub via a GitHub app. To configure Renovate for your GitHub account, go to https://github.com/apps/renovate. Renovate allows you to set Repository access to either All repositories or Only select repositories. Renovate is the only one of these three options that allows you to try it out on only one repository first, so if you’ve never used one of these bots, I’d recommend starting with Renovate on one repository.
Install Renovate
Renovate will create an onboarding pull request to the selected repositories. The onboarding PR contains basic configuration for Renovate to run. It describes the configuration in a Configuration Summary, and provides some information about What to Expect when the PR is merged (in this example, a list of PRs that will be opened).
Renovate Onboarding PRRenovate What to ExpectRenovate basic configuration
Note: These screenshots were taken from the PR created in September 2022. It may have changed since then.
Configuration
Renovate offers additional configuration options. In addition to setting a maximum number of PRs, Renovate allows you to to set a maximum number of concurrent branches or even an hourly limit, which can help to keep the number of open PRs and branches manageable. Renovate also lets you configure when to rebase (or not), and settings to help you manage the PRs assignees, reviewers, commit messages, labels, and more. Overall, Renovate offers more configuration options, and these options are more fine-grained than Dependabot’s options.
Once the onboarding PR is merged and the configuration file is added to your repository, Renovate will start opening pull requests with updates on the selected repositories.
Renovate pull request
Pull requests
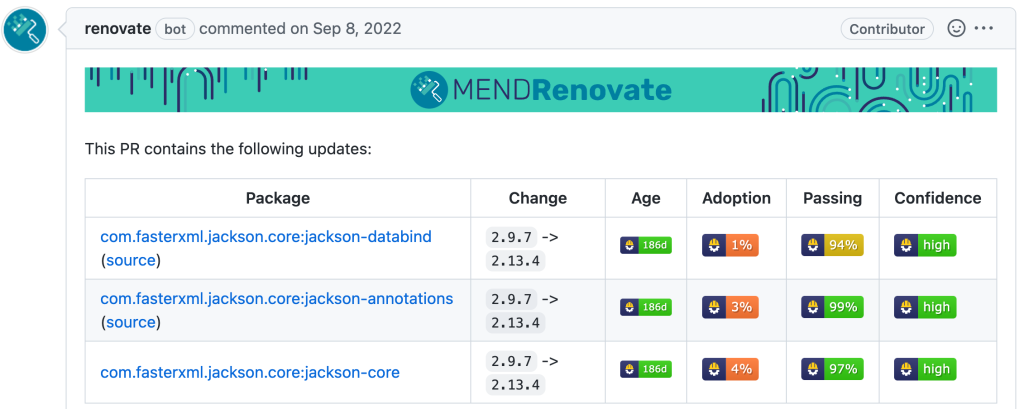
These PRs contain information about the reason a PR was created including which package was updated, the current and new version, as well as the following information to help you decide whether or not to merge the PR and apply the update (apart from your build being green).
Age: The age of the package
Adoption: The percentage of this package’s users (within Renovate) which are using this release
Passing: The percentage of updates which have passing tests for this package
In addition, Renovate offers the option for rule based auto merging of PRs; a feature that lets you automate upgrading dependencies. When auto merging is enabled, Renovate tries to merge the proposed update once the tests pass. Renovate recommends that you enable auto merge only for any type of dependency updates which you would just merge anyway, and keeping auto merge disabled for updates where you want to review the release notes and/or code before merging. Of course, great test coverage is also very helpful here! Renovate is currently the only of these three options that offers this feature.
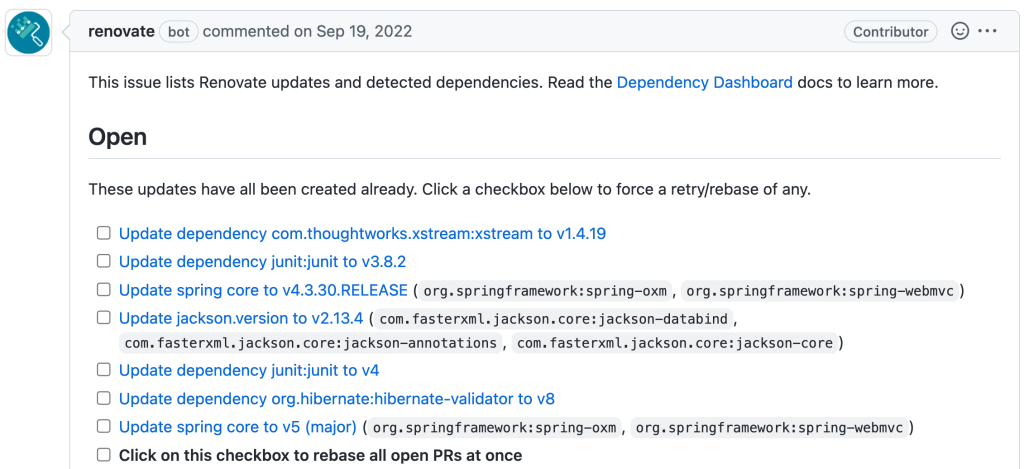
Dashboards
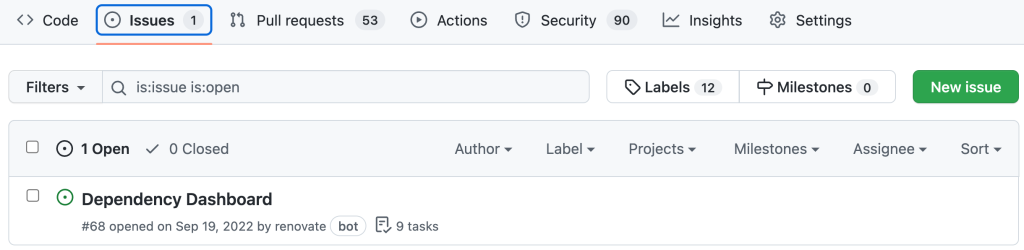
Finally, Renovate will add a Dependency Dashboard to your project, listing all Renovate updates and detected dependencies. This dashboard can be enabled or disabled as desired.
In addition, Renovate provides a general dashboard with all projects & jobs run, which you can find under https://app.renovatebot.com/dashboard if you have Renovate enabled.
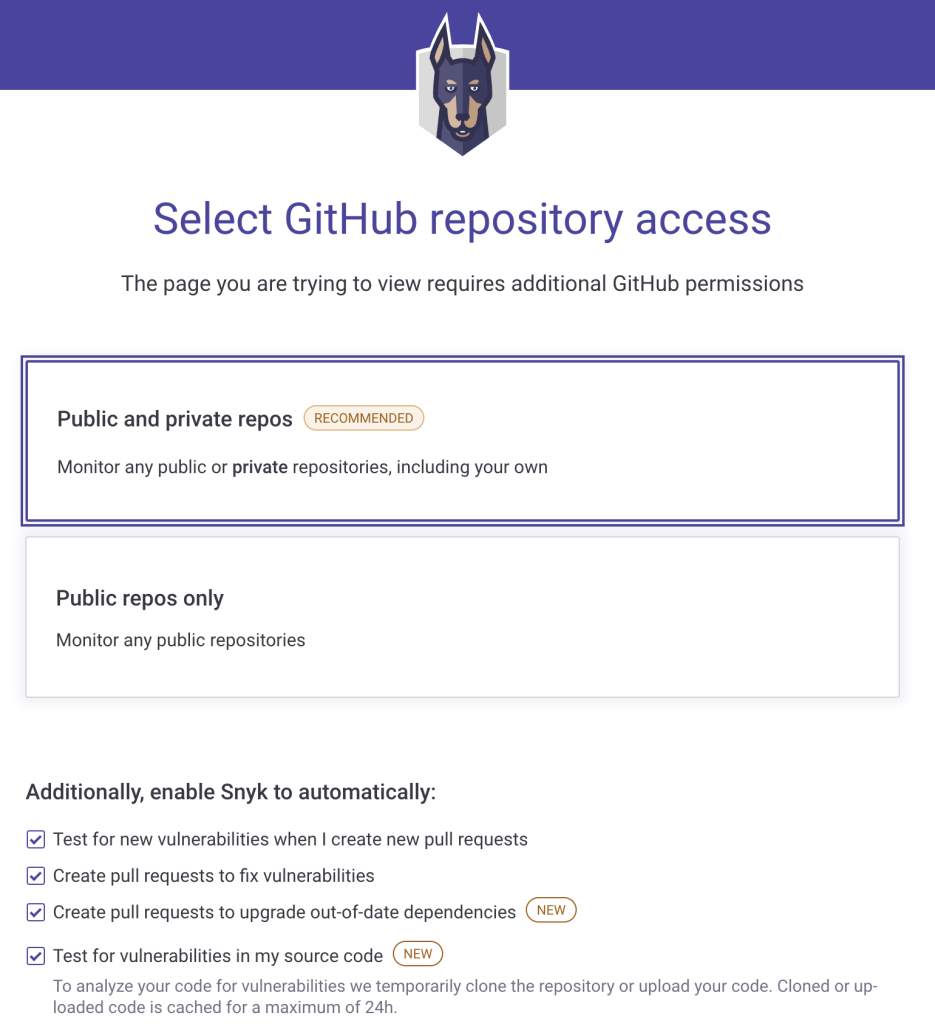
Snyk Open Source is available from Snyk. There are more steps to enable it for your GitHub Profile, but it also offers more features. To enable Snyk Open Source, go to https://snyk.io/product/open-source-security-management/ and select Start free. You will need to Authorize snyk on your GitHub profile, select repository access (either Public and private repos or Public repos only), select other available features you want to use, and provide a Personal access token on GitHub.
Snyk Open Source Start free
Features
In addition to security updates, version updates, and dashboards, Snyk Open Source offers to test for new vulnerabilities and/or test for vulnerabilities in source code. These options are currently not offered by Dependabot or Renovate. As this blog post focussed on tools to help you detect possible vulnerabilities in your dependencies and automatically create PRs to upgrade them, we will not look at scanning the source code for vulnerabilities here.
Snyk Open Source GitHub repository access and additional features
Pull requests
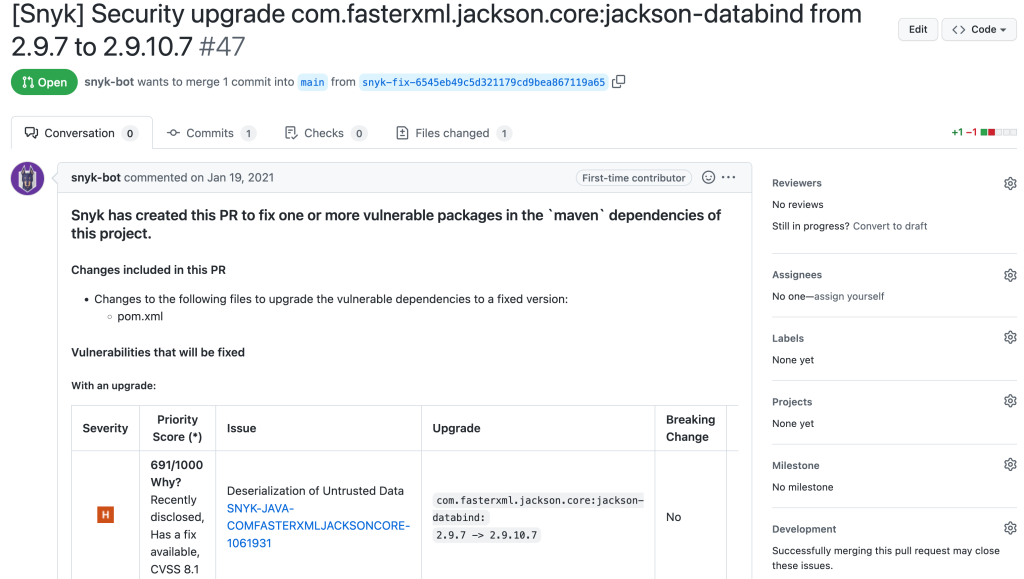
When enabled, Snyk Open Source will open PRs on the selected repositories. These PRs also include information about the reason for the PR, severity of a vulnerability, priority score and why it has this score, details of the version upgrade (current and new version), and more.
Snyk Open Source pull request
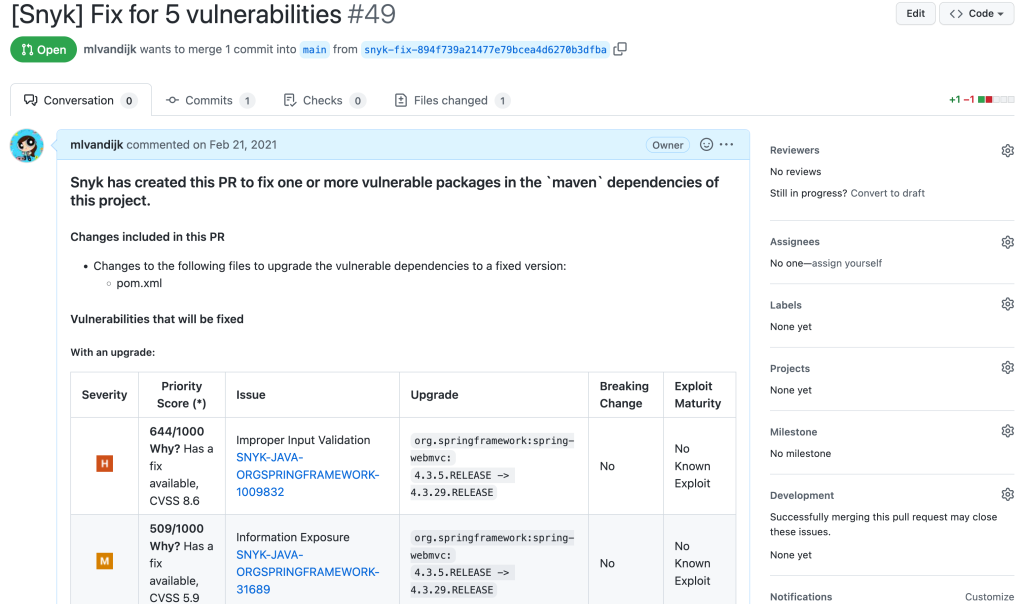
By default, Snyk Open Source will combine related updates into one single PR to help reduce the noise. Dependabot does not currently offer this option, while Renovate can be configured to do something similar.
Snyk Open Source combined PR
Snyk Open Source also has the option to test for new vulnerabilities. When enabled, incoming PRs will be checked for known vulnerabilities to make sure that no known vulnerabilities are added to the code base. Dependabot and Renovate do not currently offer this feature.
Snyk Open Source security test on PRs
Configuration
We can configure the frequency with which Snyk Open Source should run (daily, weekly, never). We can enable or disable scanning for new and/or known vulnerabilities, so we can clear our backlog of known vulnerabilities separately from making sure we don’t get any new vulnerabilities. This might help getting started with updating outdated dependencies without getting overwhelmed with too many updates. Dependabot and Renovate do not currently offer this option. Finally, we can also enable or disable PRs for a single project, so we can start using Snyk Open Source on a single project like we can with Renovate, but this is not a default option.
Dashboards
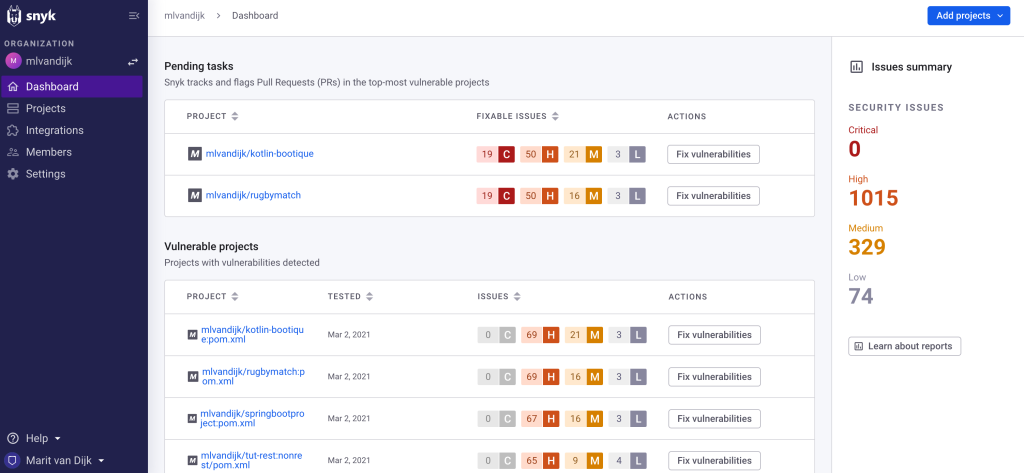
The dashboards offered by Snyk Open Source are the most extensive of these three options. The dashboards provide an overview of known vulnerabilities found in your repositories with the number of vulnerabilities and their severity visible per project and overall.
Snyk Open Source Dashboard
Integration
You can use Snyk Open Source in the Snyk Web UI, with the Snyk CLI, in your IDE, or with an API. For more information, see the Snyk Open Source documentation.
Conclusion
As we have seen, the different bots offer different features. All of the options discussed here can automatically open pull requests for vulnerable dependencies and version upgrades. The information they provide with these PRs differs, as do the number and type of configuration options. Which bot is right for you will depend on needs and preferences.
In this tutorial, we’re going to take a look at managing dependencies in IntelliJ IDEA. We’ll look at different ways to add dependencies to your project, and how to add, upgrade and remove dependencies using Package Search.
Add dependencies
There are several ways to add new dependencies to your project.
From the build file using copy-paste
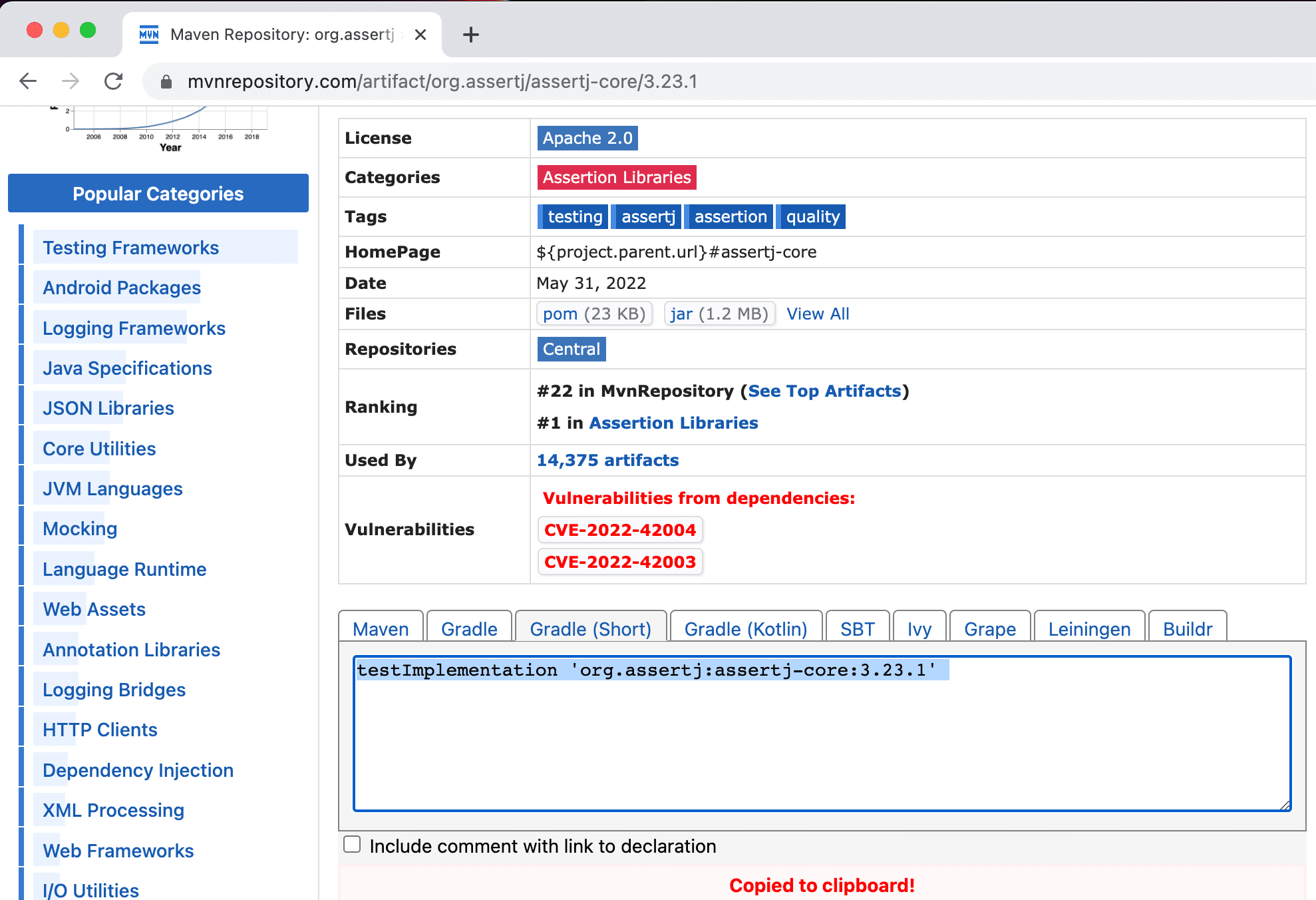
You have probably copied a dependency from Maven Repository (or another website) and pasted into your build file.
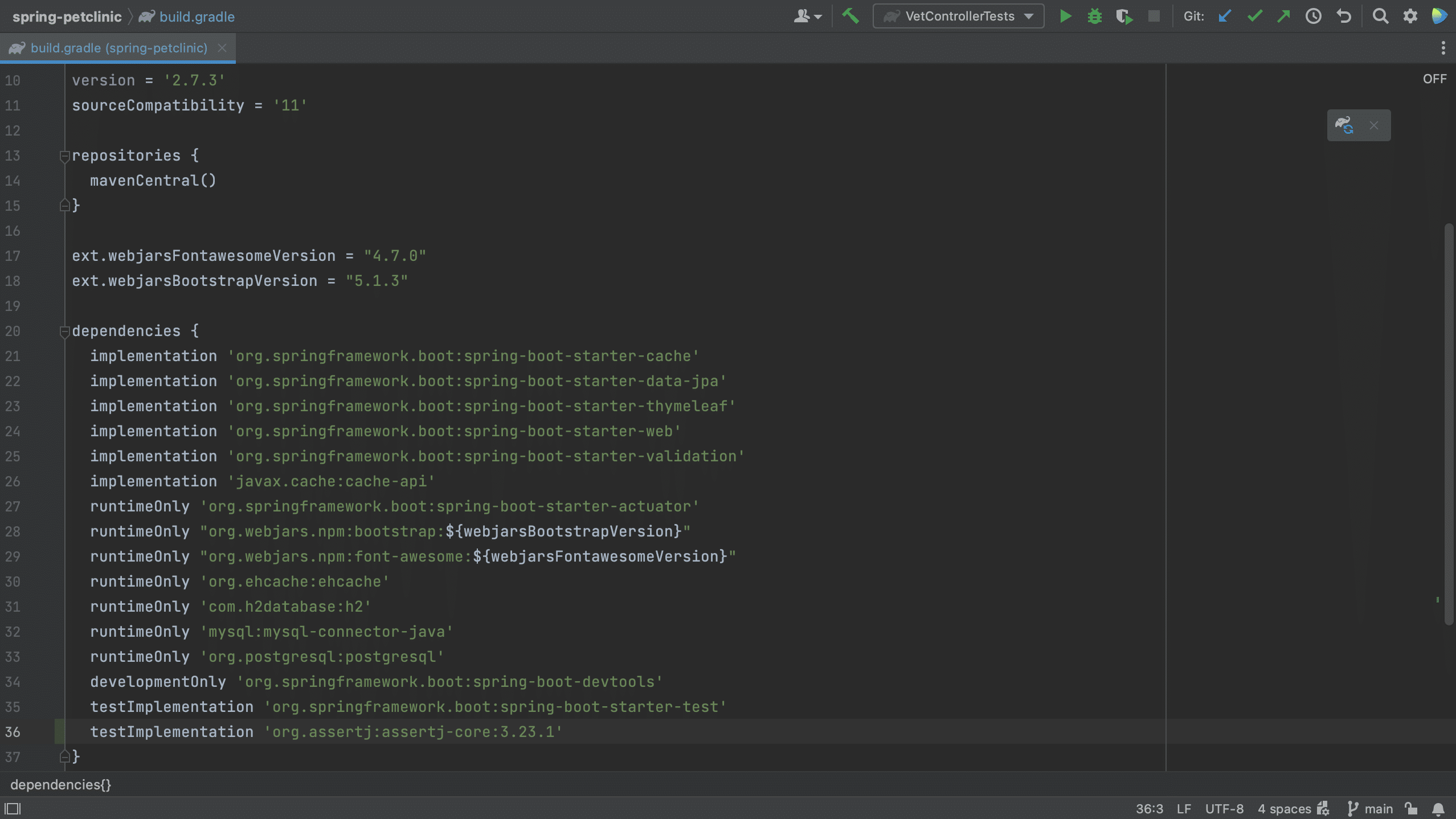
For example, we can copy the Gradle format for this dependency and paste it into our build.gradle file.
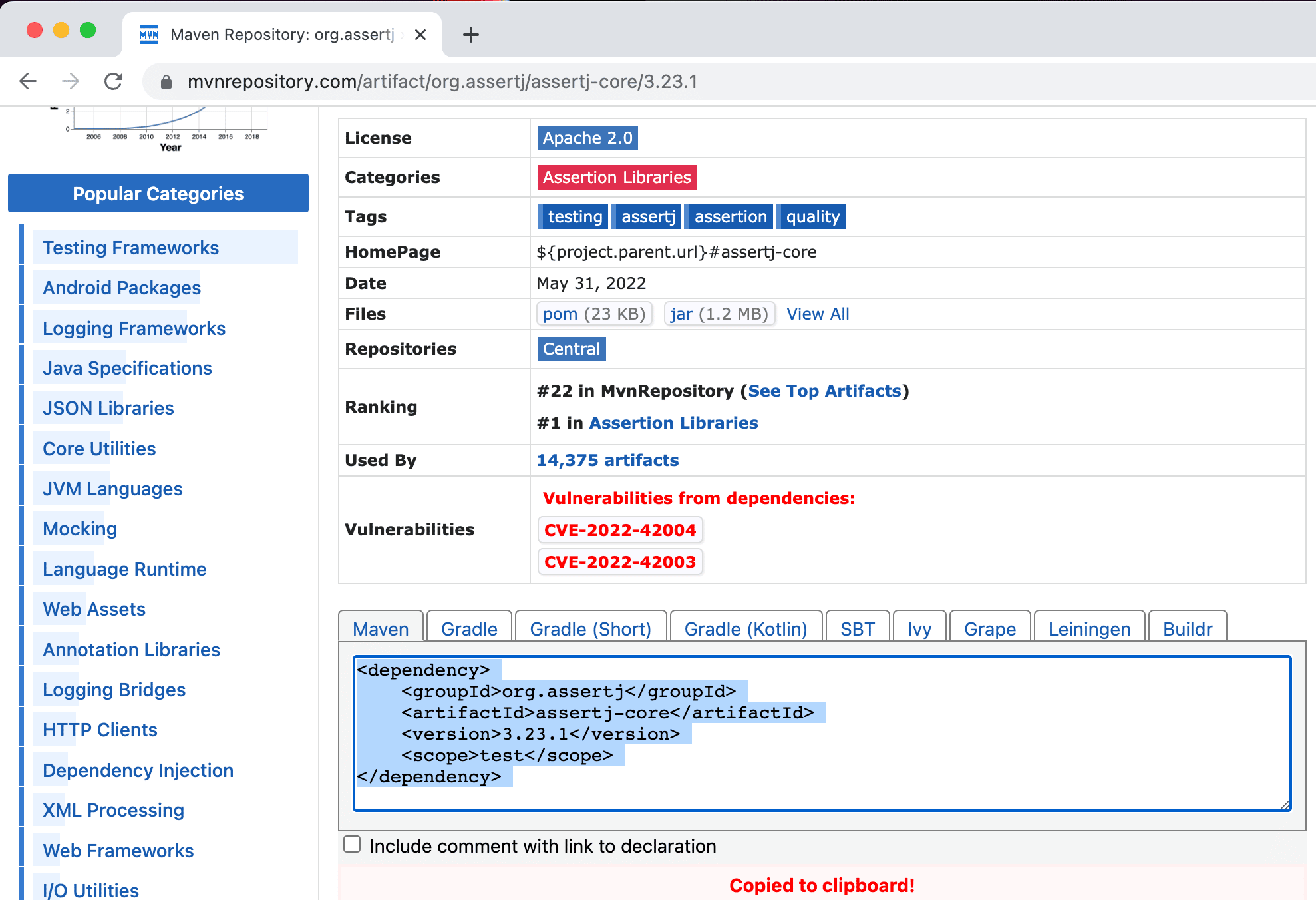
Or, if we are using Maven, we can copy the Maven xml format into our pom.xml.
Did you know that if you copy-paste a Maven XML dependency into your build.gradle file, IntelliJ IDEA automatically turns it into the correct format for Gradle?
From the build file using code completion
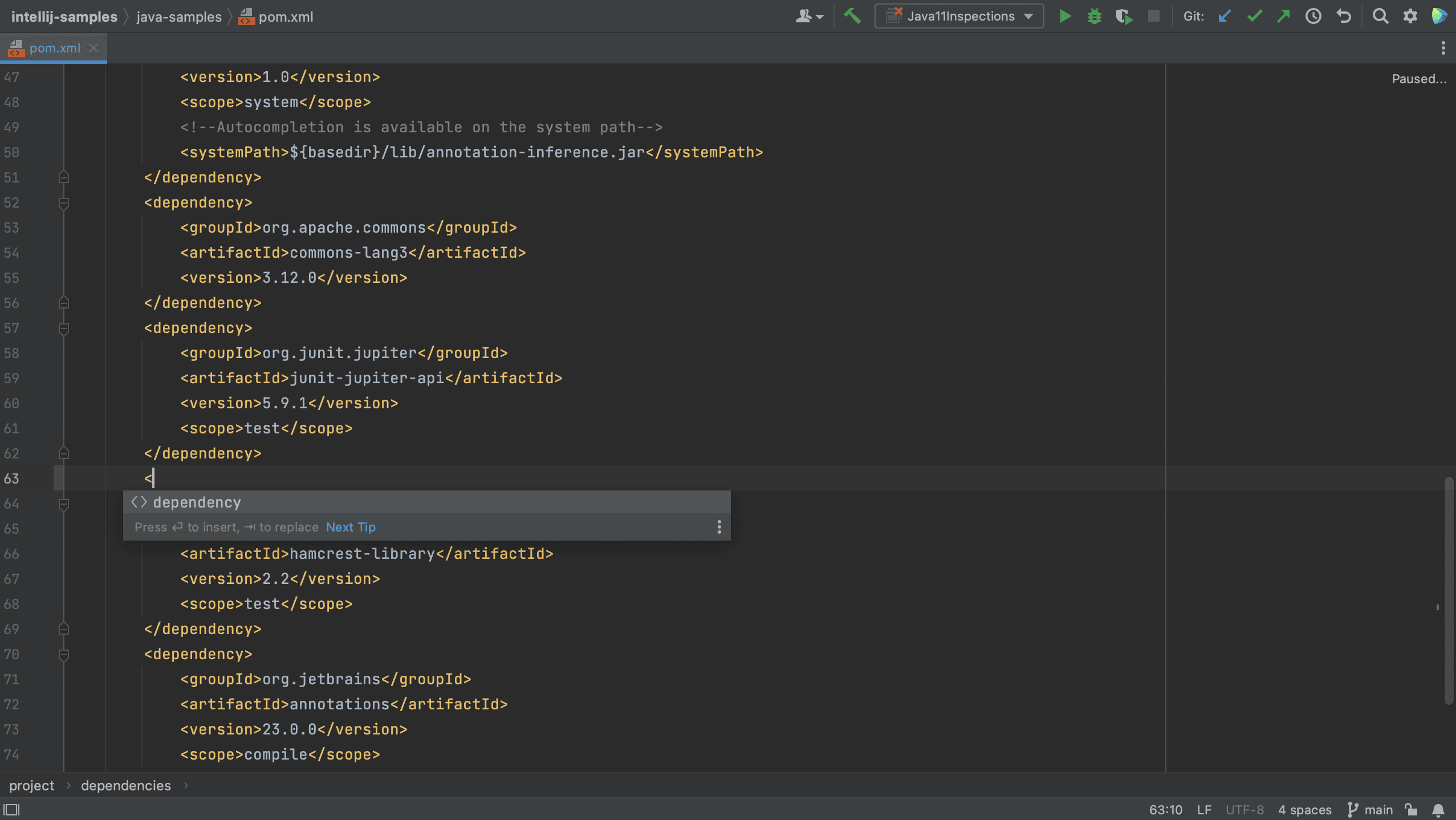
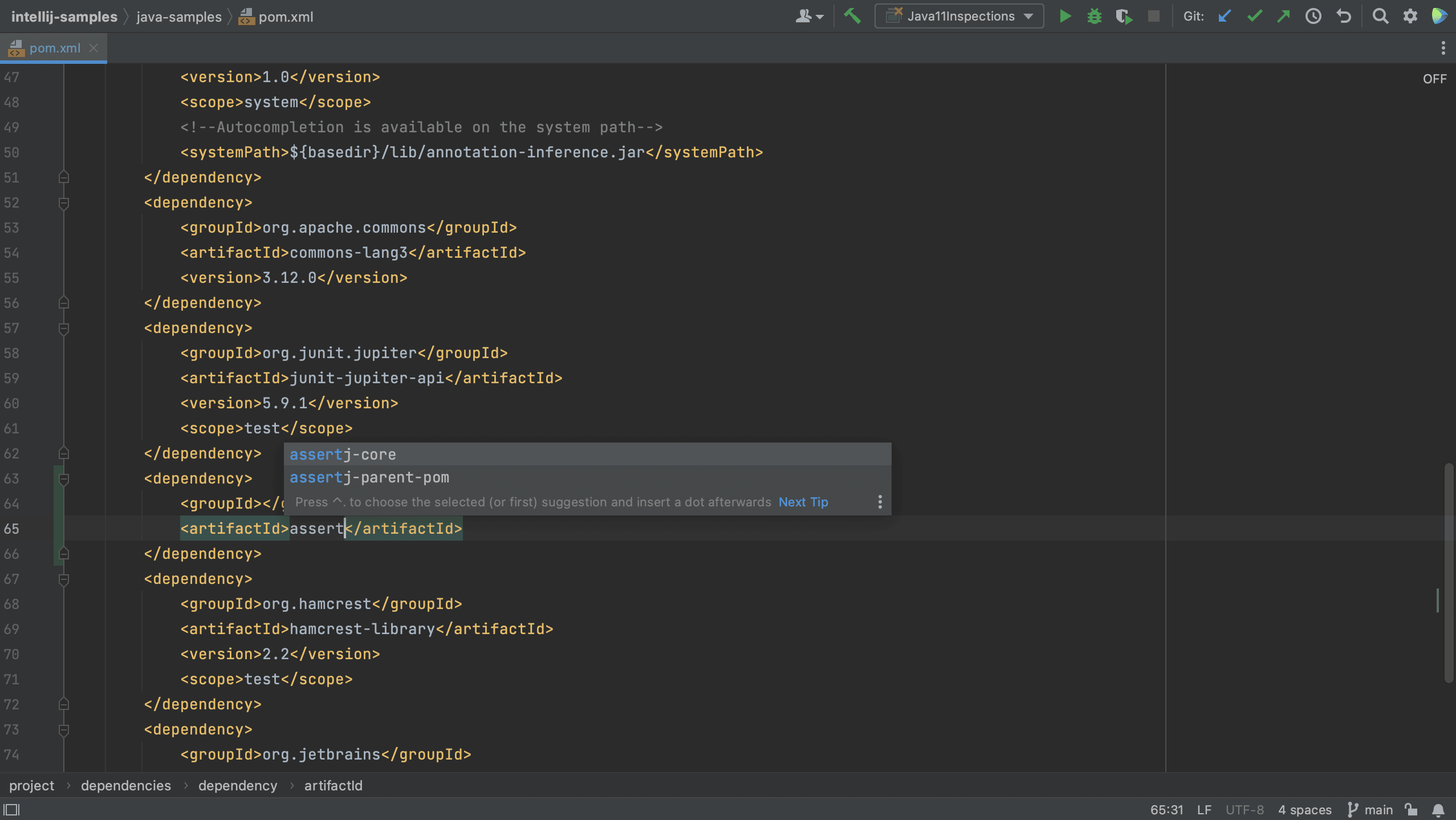
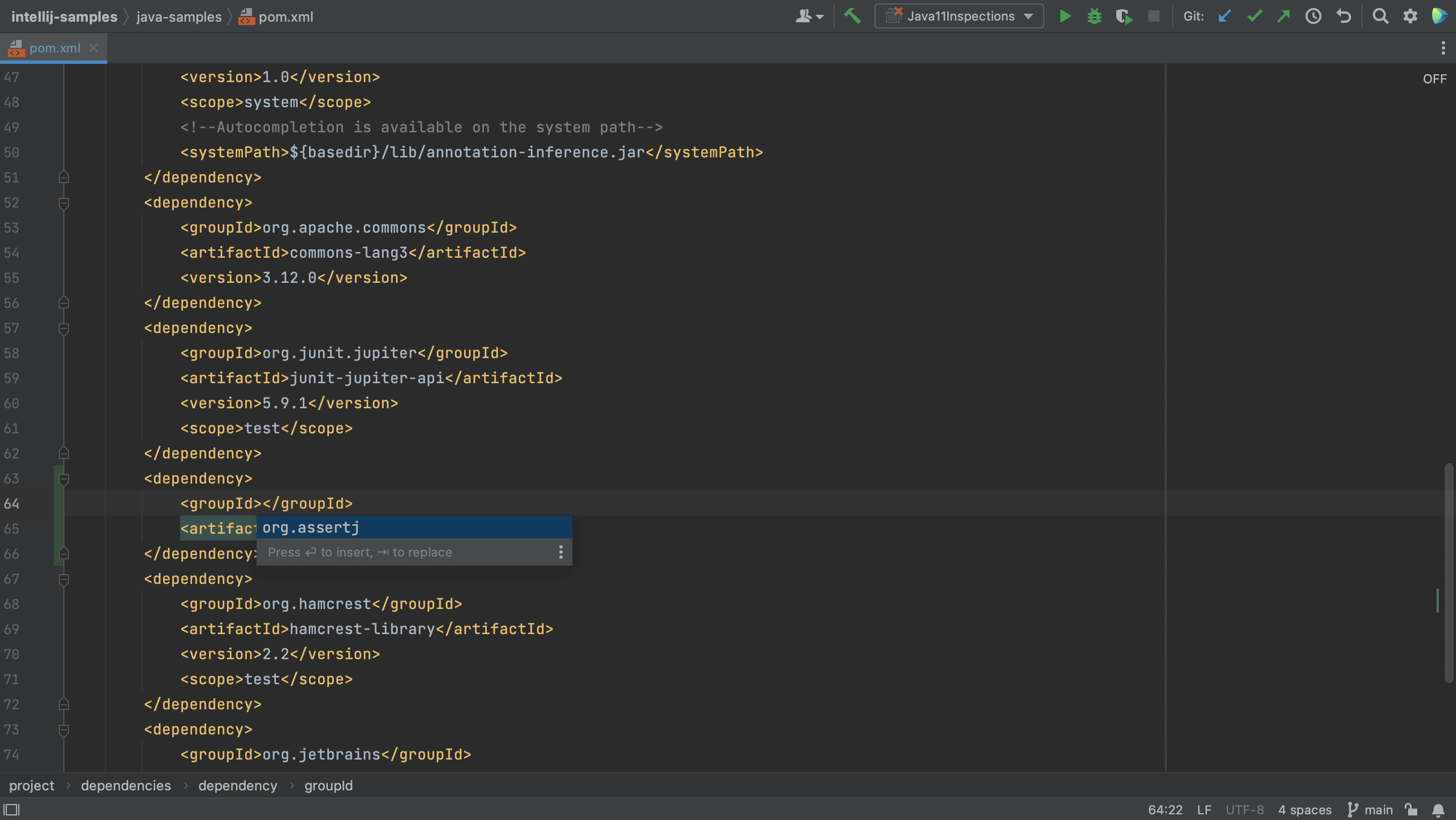
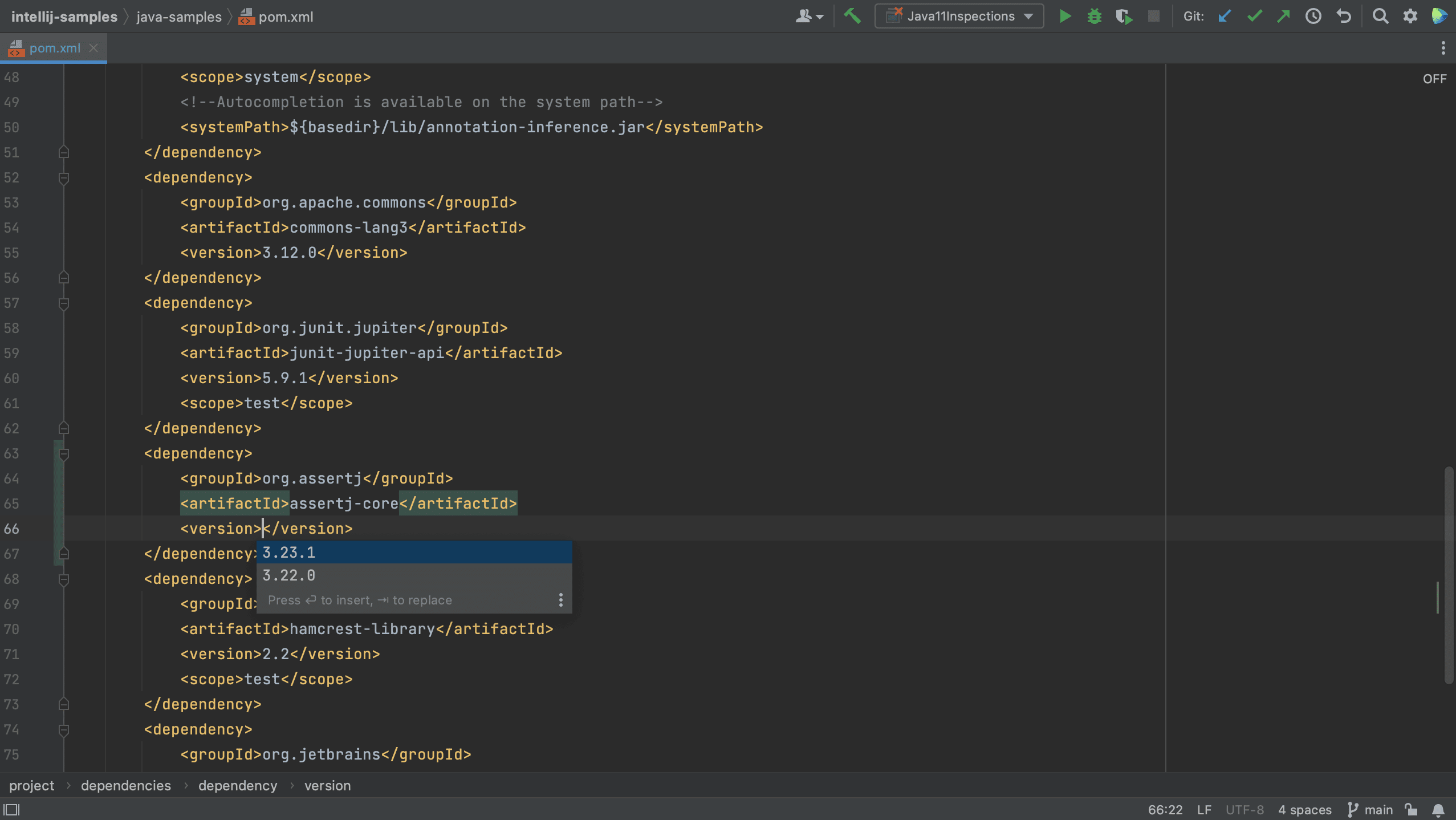
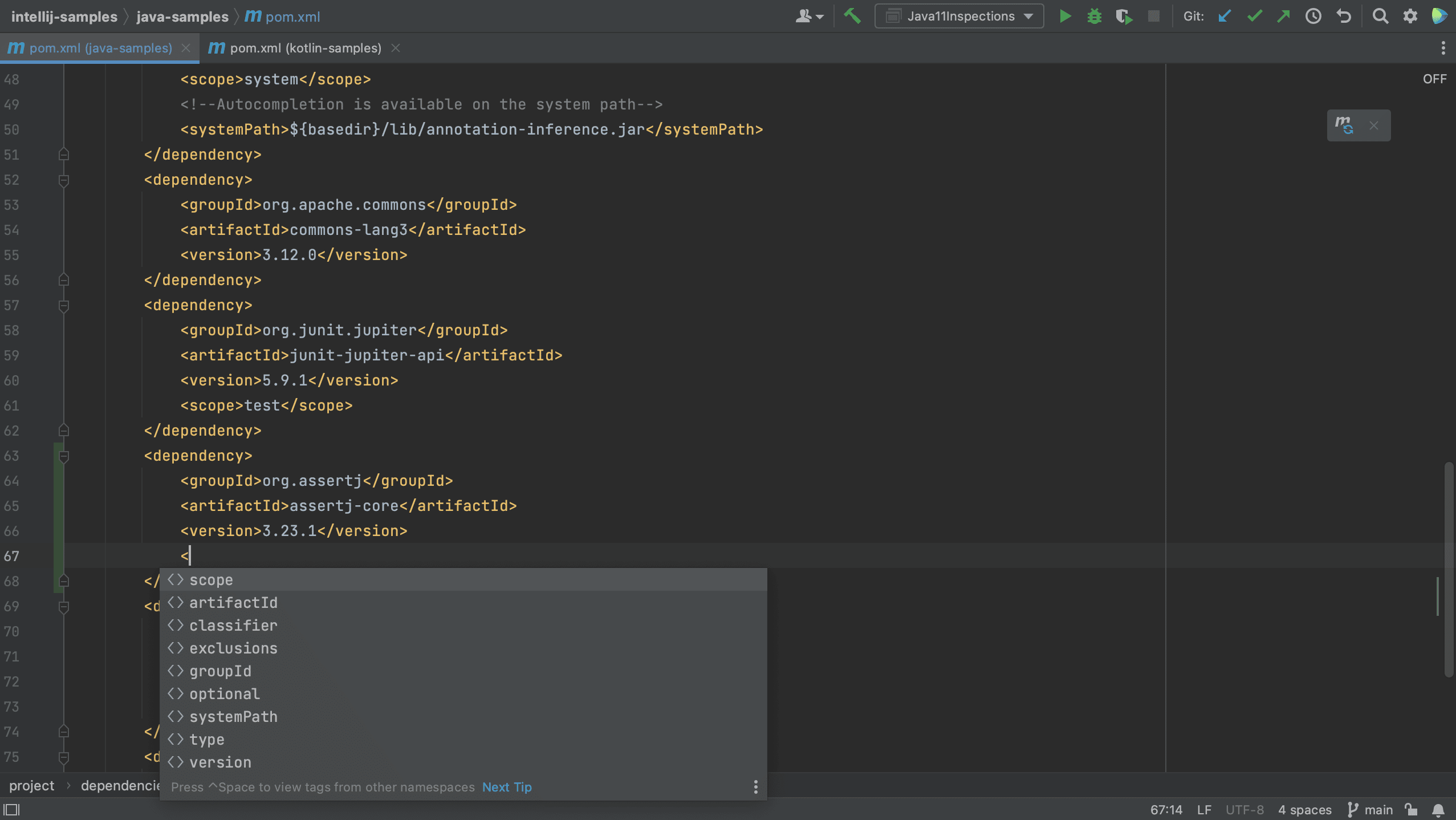
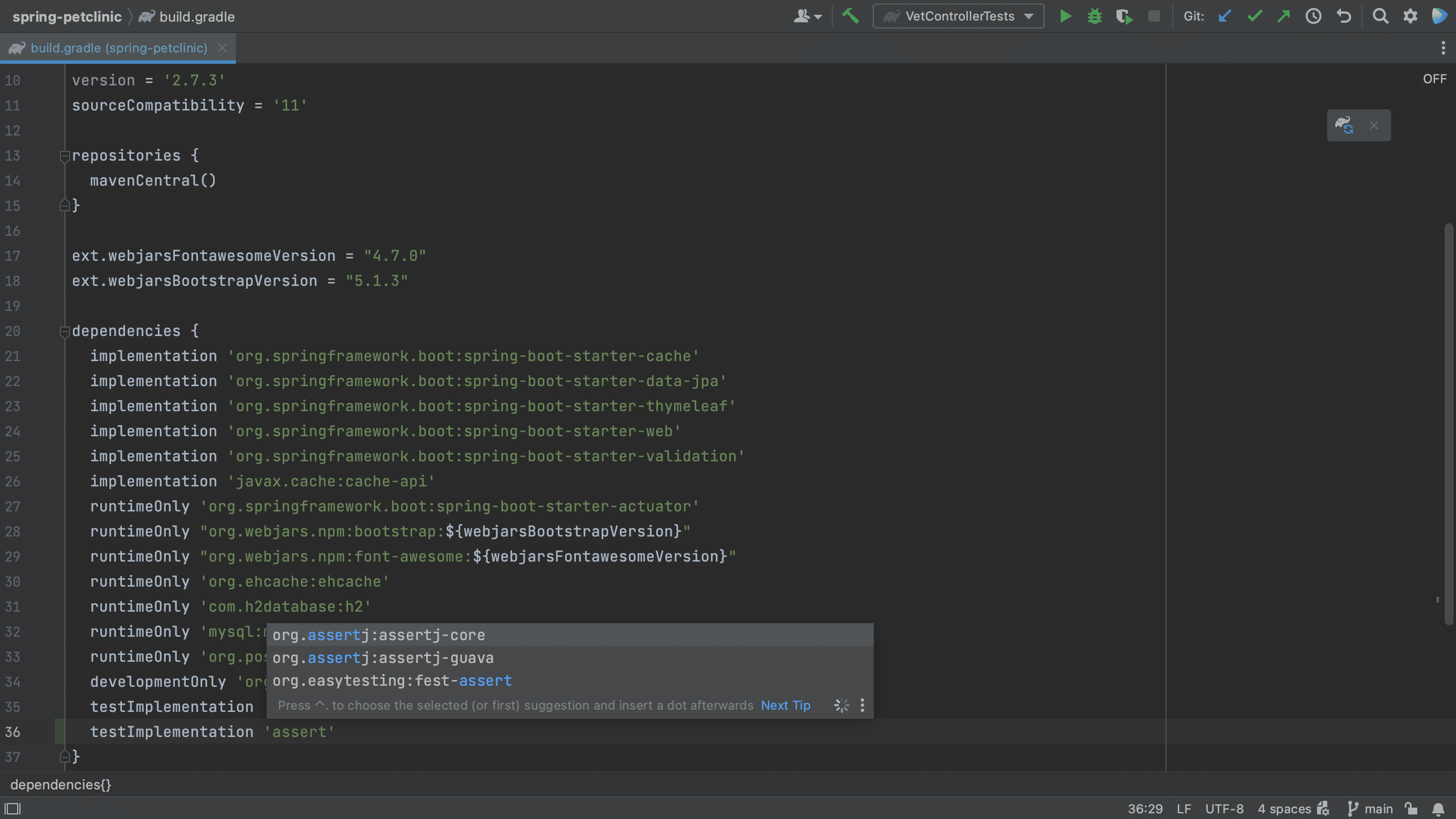
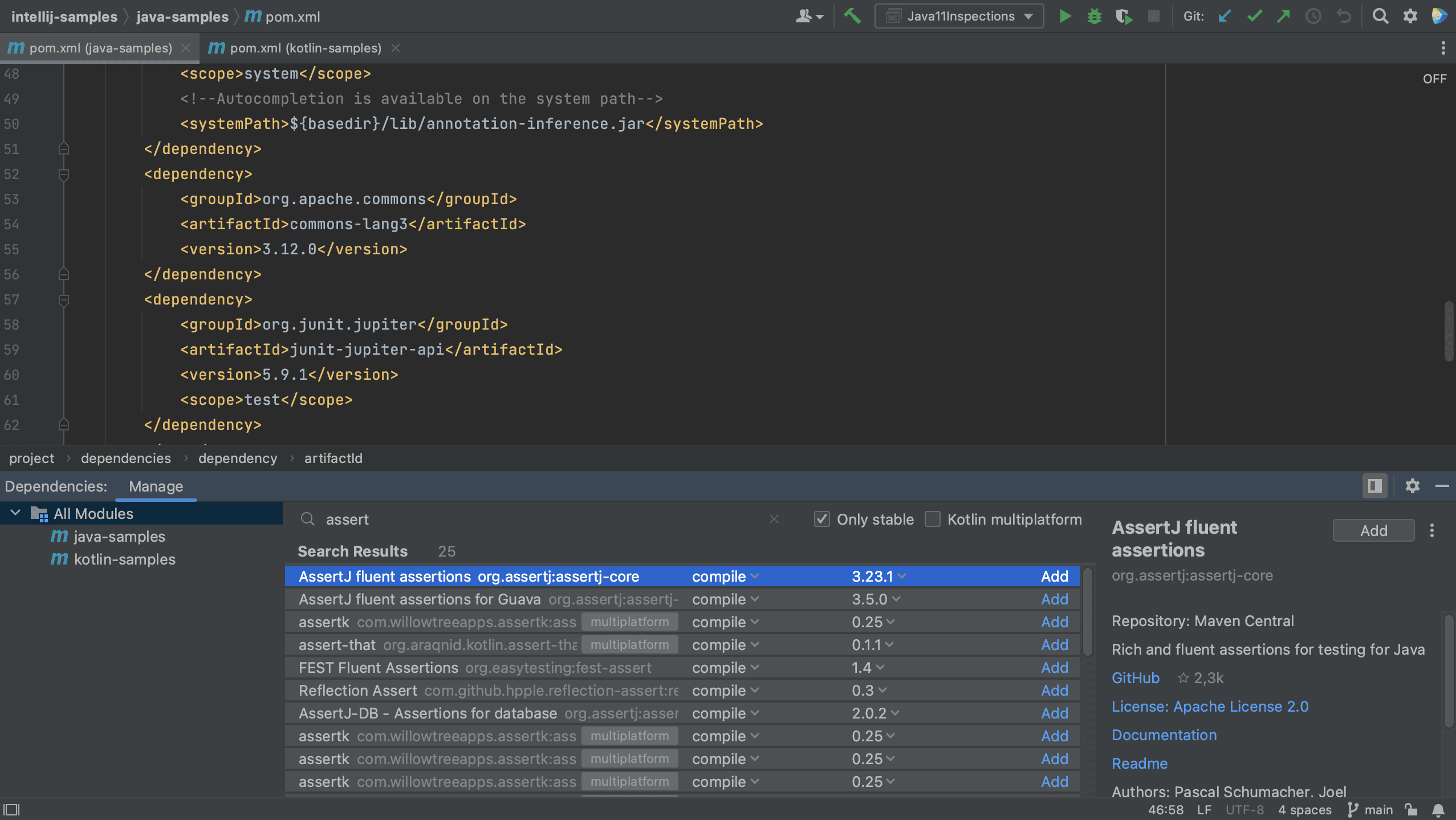
We can also add dependencies to our build file using code completion. For example, let’s add a new dependency to our pom.xml.
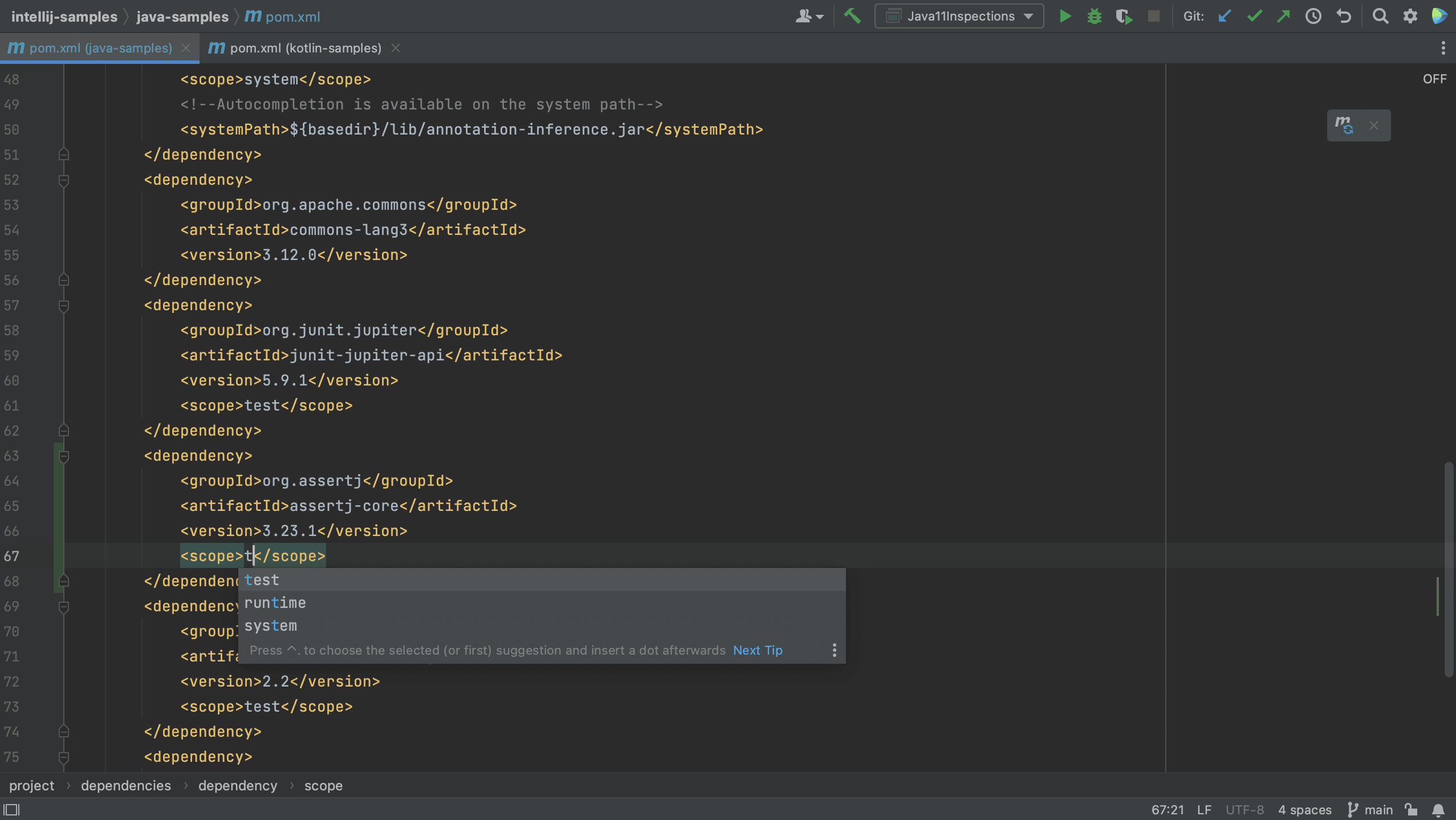
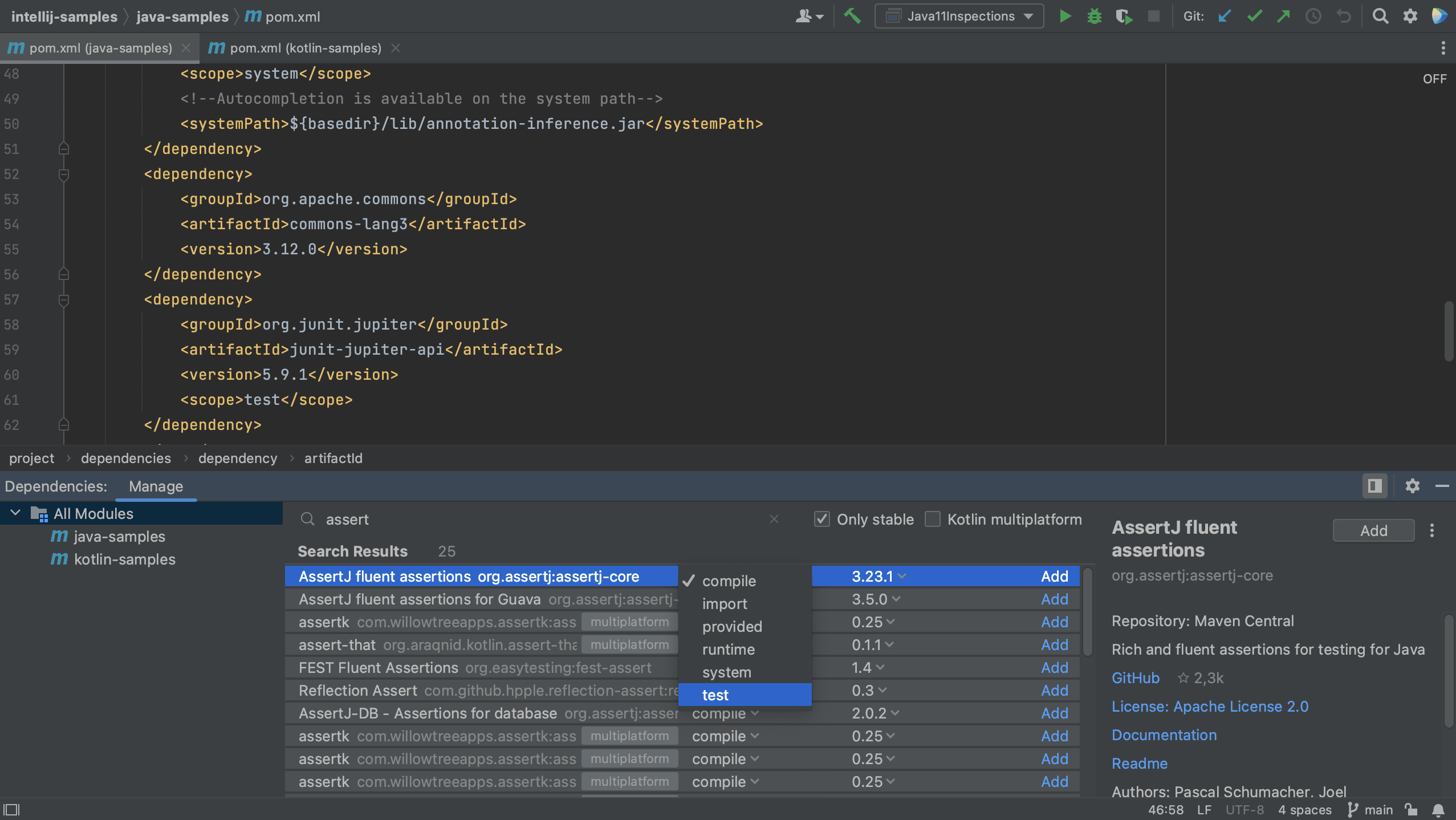
We see that IntelliJ IDEA autocompletes the dependency xml, and we can search for the dependency we want, in this example AssertJ. If needed, the version number will also be added. Since this is a test dependency, we need to add the test scope, still using code completion.
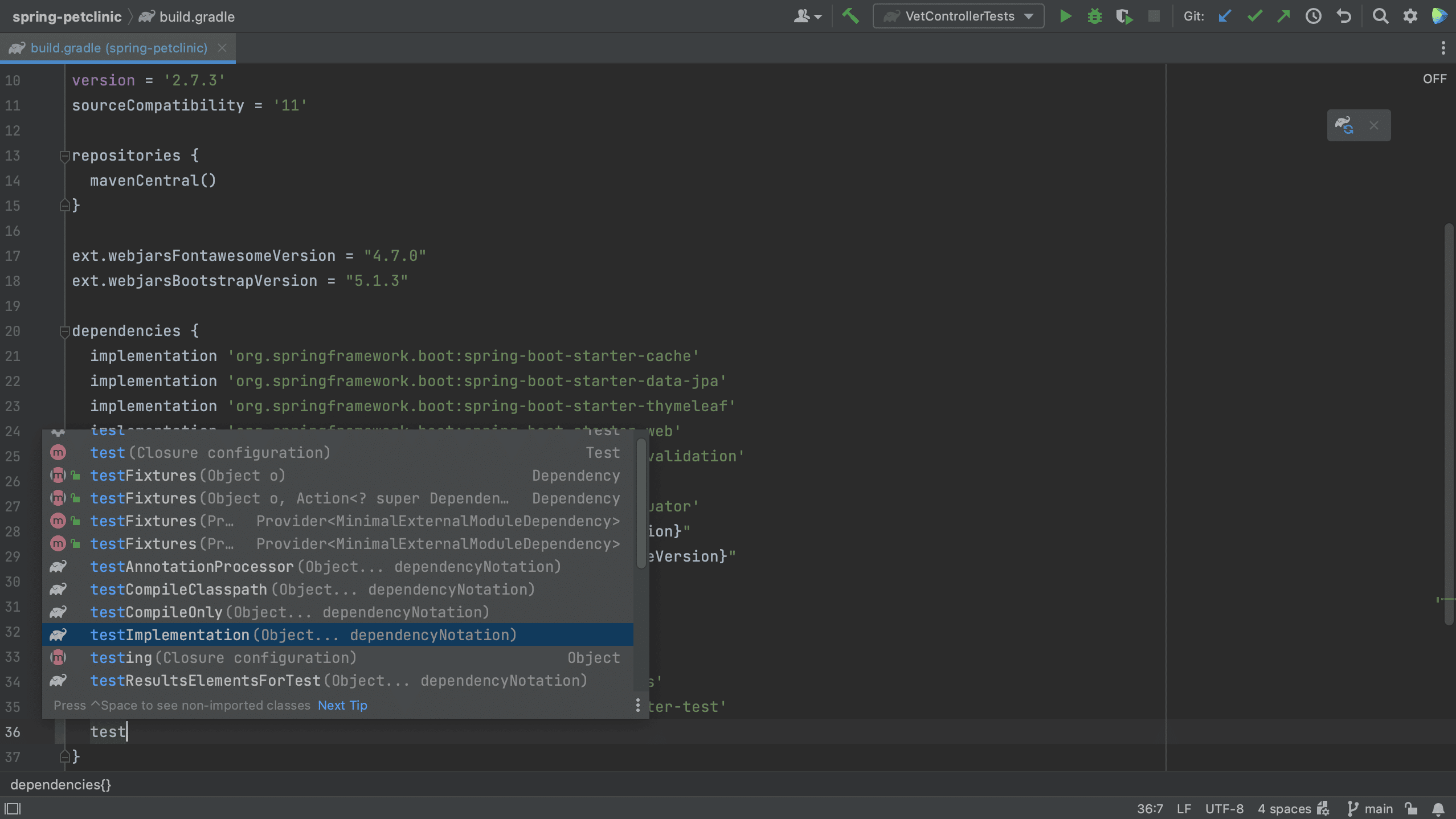
Code completion works in Gradle too, as you can see below.
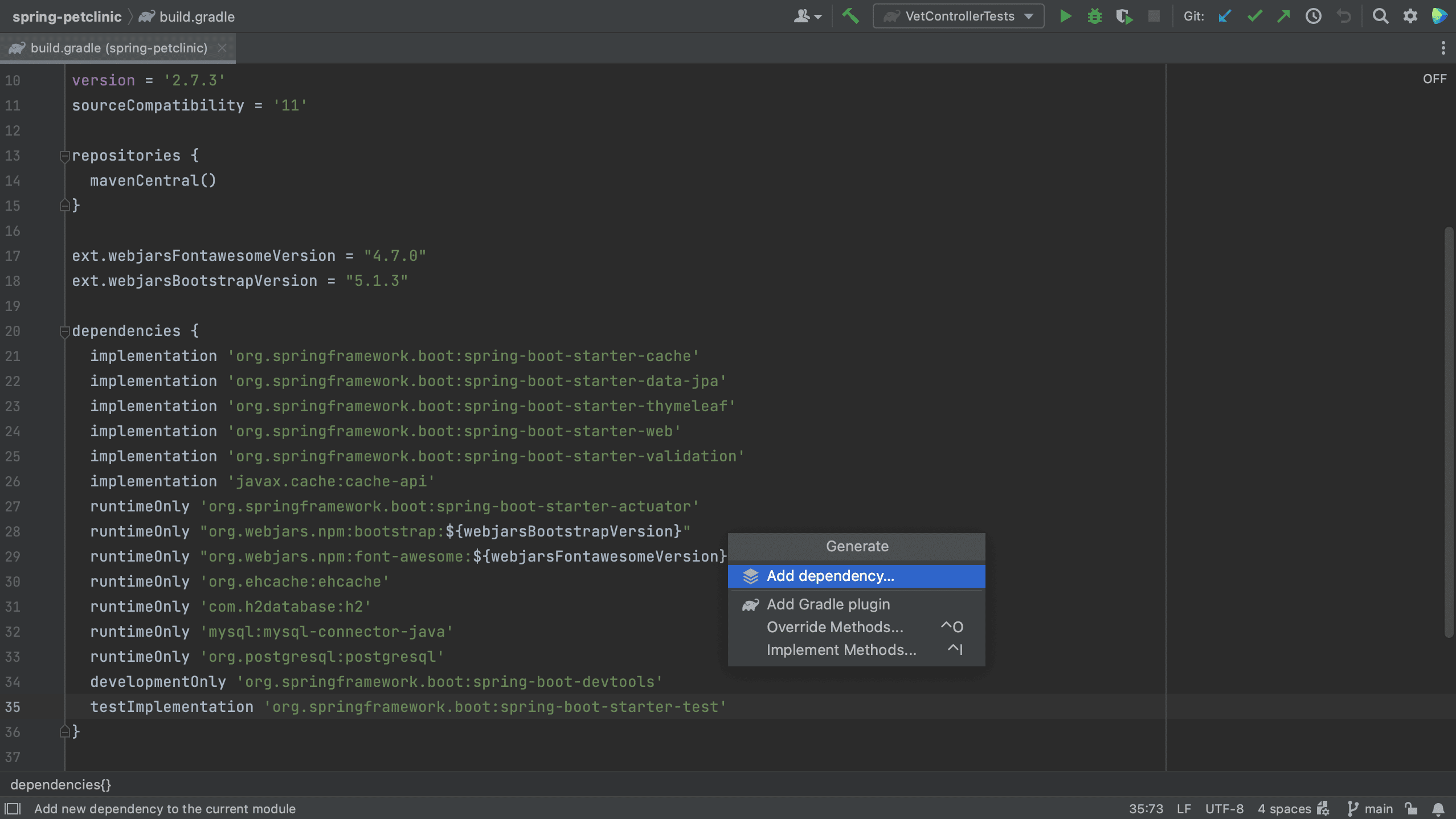
From the build file using code generation
We can also use code generation from the build file to add dependencies. In the build file, the pom.xml in a Maven project, invoke Package Search using ⌘N (on macOS) or Alt+Insert (on Windows & Linux) and in the menu that opens, select Add dependency. This will open the Dependencies tool window.
Note that if we are using Gradle, we can do the same in our build.gradle file.
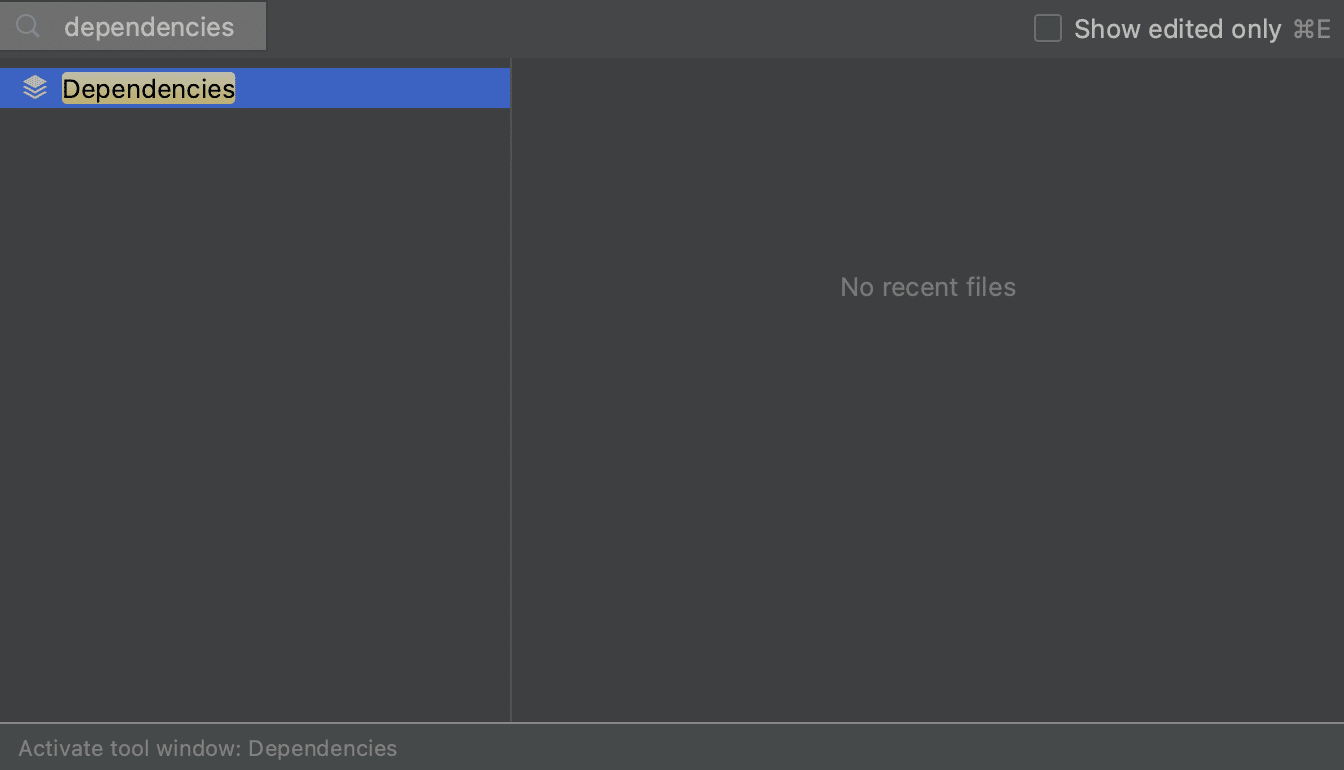
From the Dependencies tool window
Alternatively, we can open the Dependencies tool window directly. There is no shortcut to open the Dependencies tool window, so we can either use Recent Files, ⌘E (on Mac) or Ctrl+E (on Windows/Linux), and type in “dependencies” to open the Dependencies tool window.
Alternatively, we can open it by clicking Quick Launch in the bottom-left and selecting Dependencies.
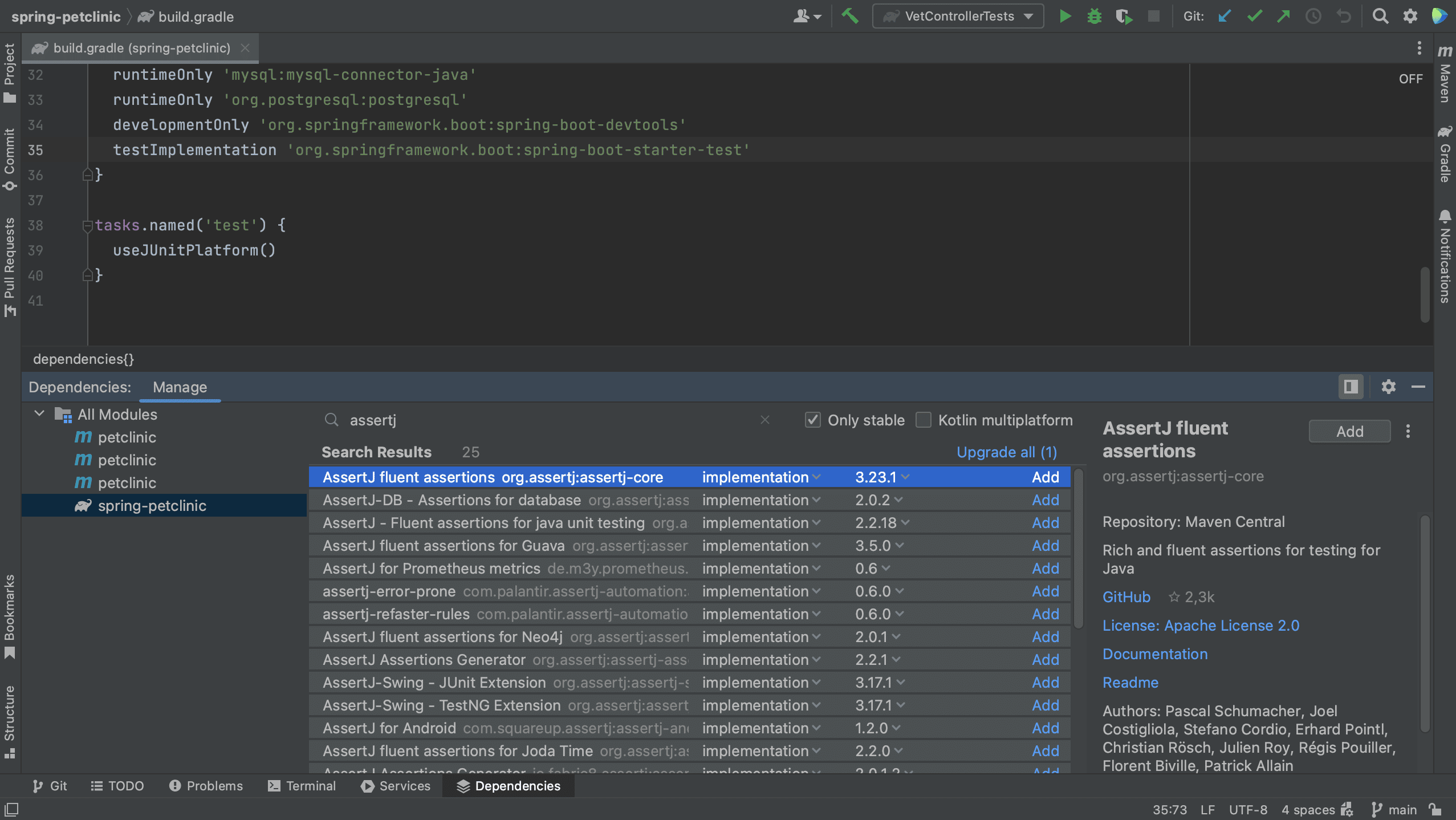
In the Dependencies tool window, we can search for a dependency. For example, let’s search for AssertJ.
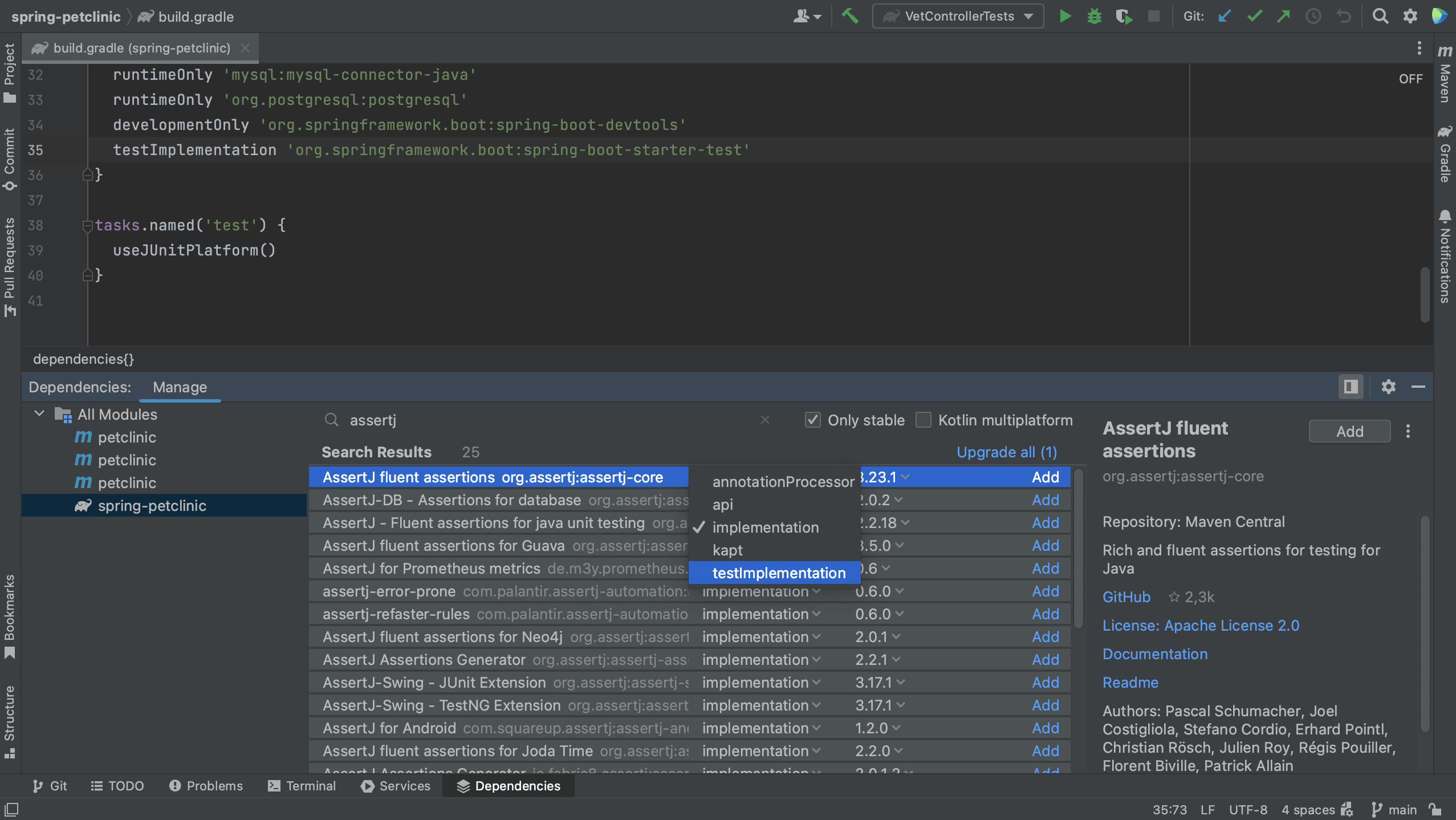
Note that we can select a scope for this dependency. The names of the scopes are based on the build tool with which you are working. Since this is a test dependency, and we are using Gradle in this project, we can set the scope to testImplementation.
We can also select the version we want to use.
We can do the same in Maven.
Note that the names of scopes for Maven are different from Gradle. In Maven, we can set the scope for a test dependency to test.
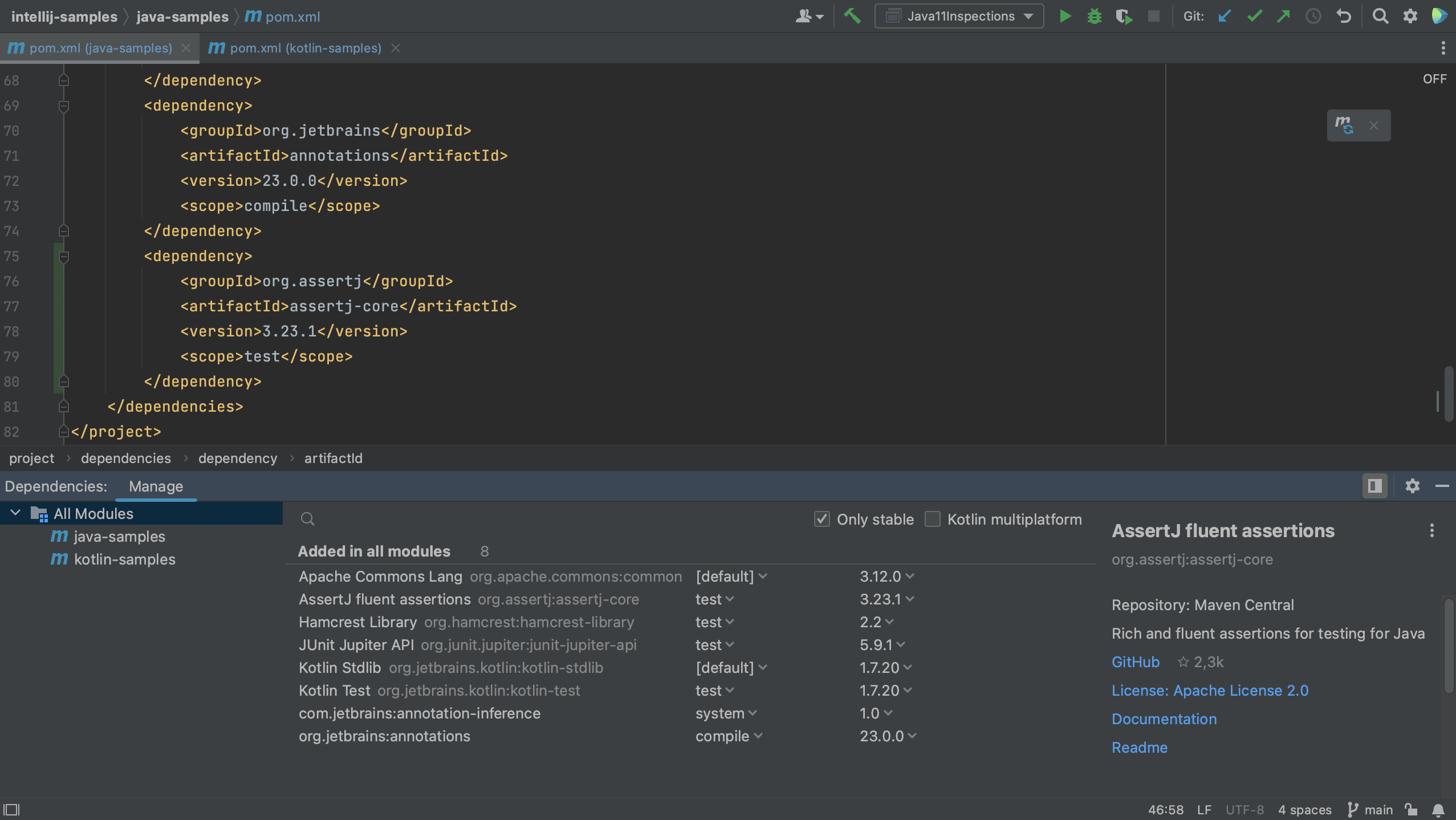
When we click Add, we see that the dependency is added to the build file.
If the version number is shown in red, that means IntelliJ IDEA hasn’t downloaded this library before. Click Load Maven Changes so IntelliJ IDEA will update its dependencies based on the changes to the pom.xml or build.gradle file.
Go back to the Dependencies tool window and clear the search box by clicking the x on the right-hand side. You’ll see the project’s dependencies are updated with your new dependency.
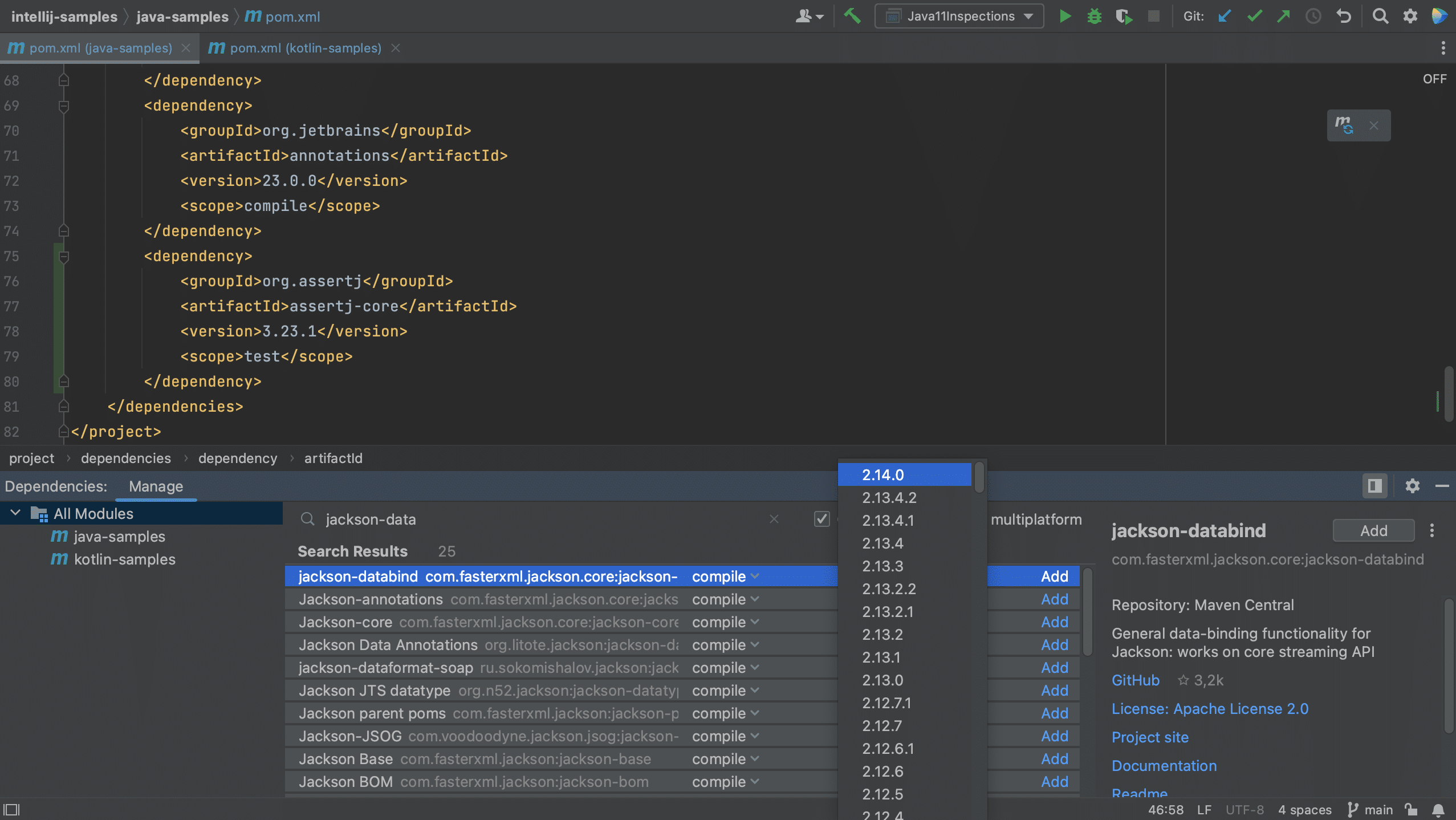
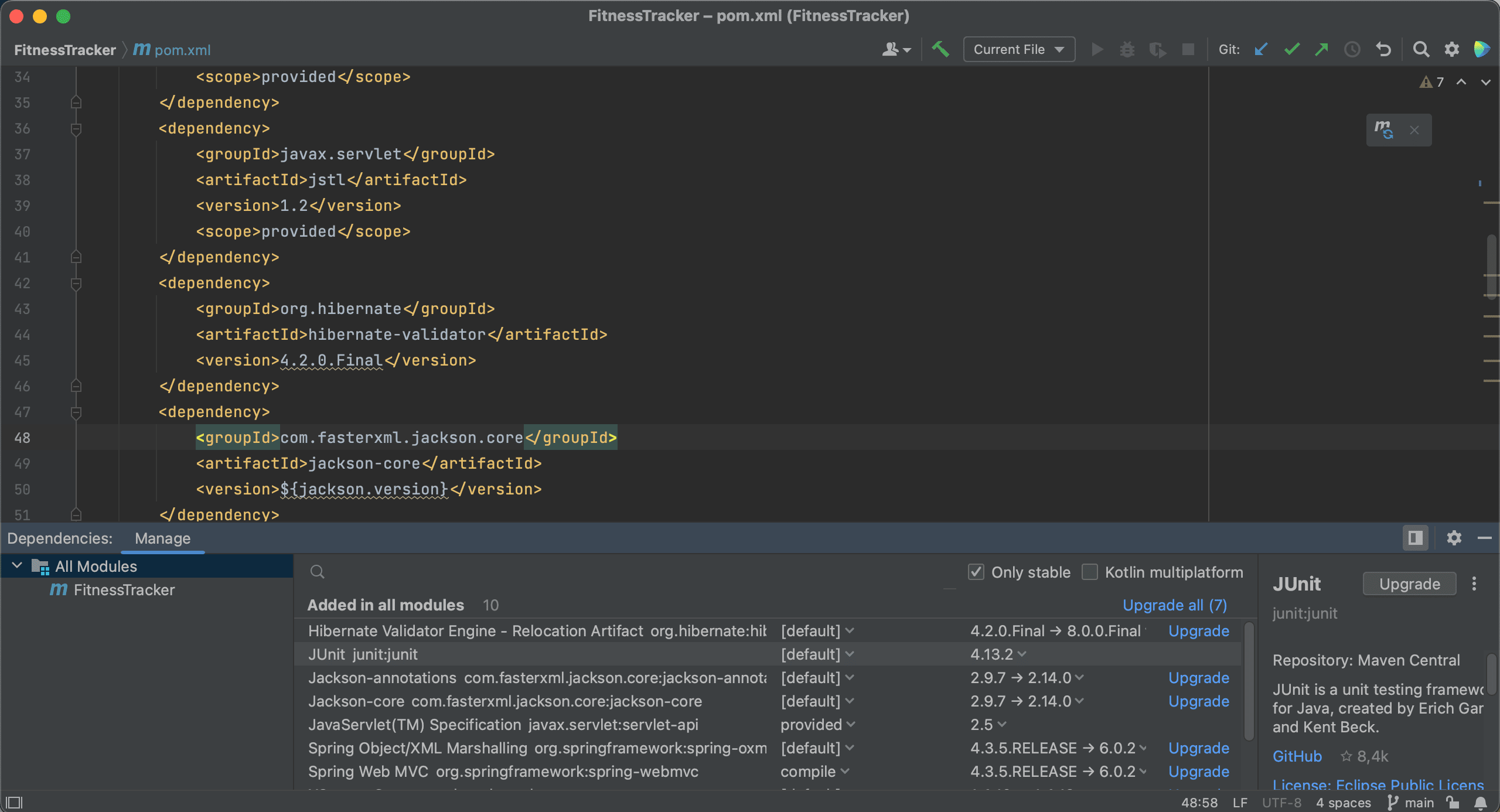
Next, let’s look for jackson-databind. We see that there are several versions available. Since we have selected Only stable, only stable versions are shown in the list.
If we uncheck this option, we see that the list of versions also includes the release candidates.
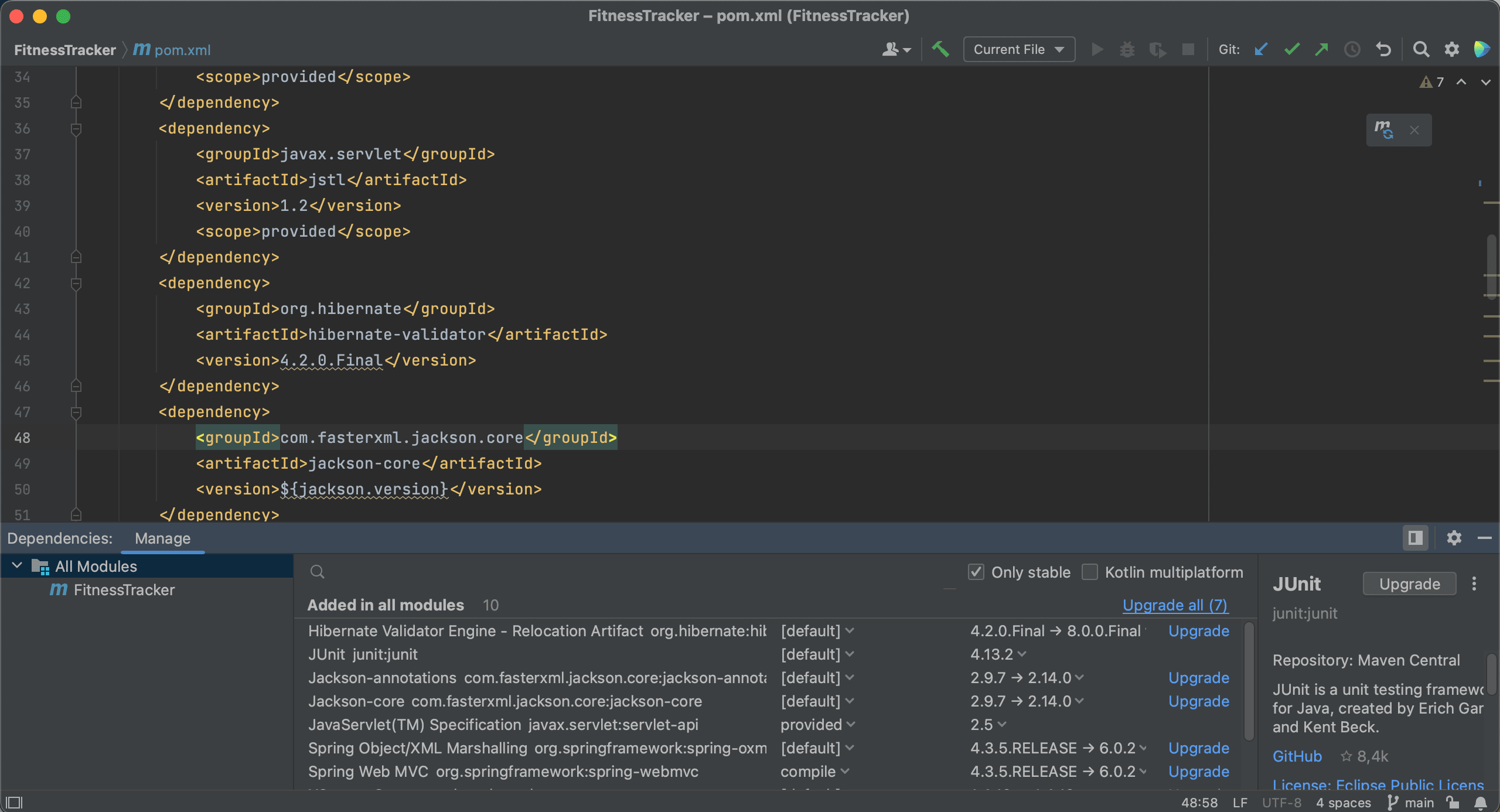
For production code, we probably want to use stable versions, so let’s select the Only stable checkbox again. With this option enabled, IntelliJ IDEA will exclude any dependencies that have no stable versions, and hide them from the list. Now we can select the latest stable version and add this to our project. Let’s also Load Maven Changes again.
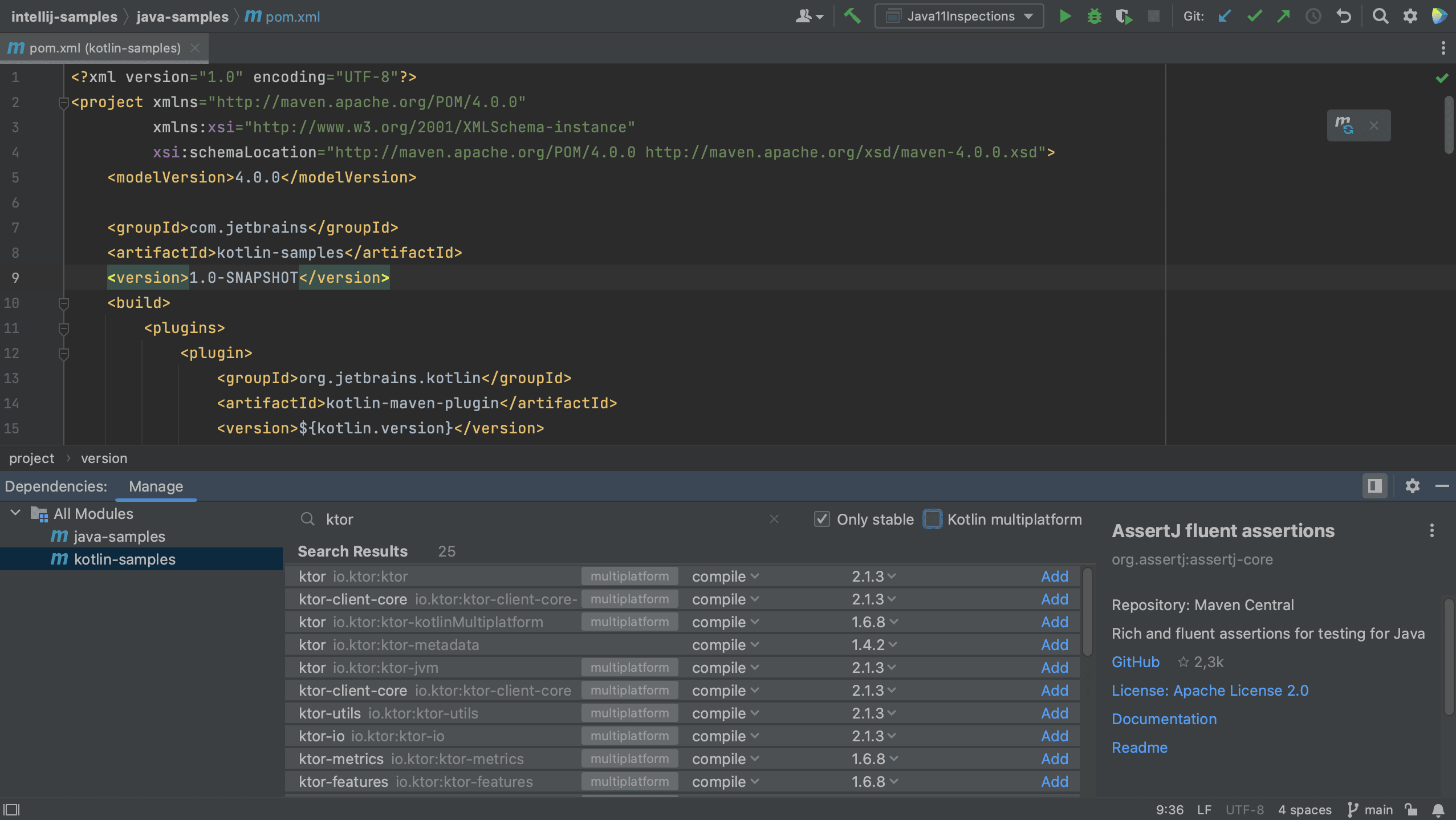
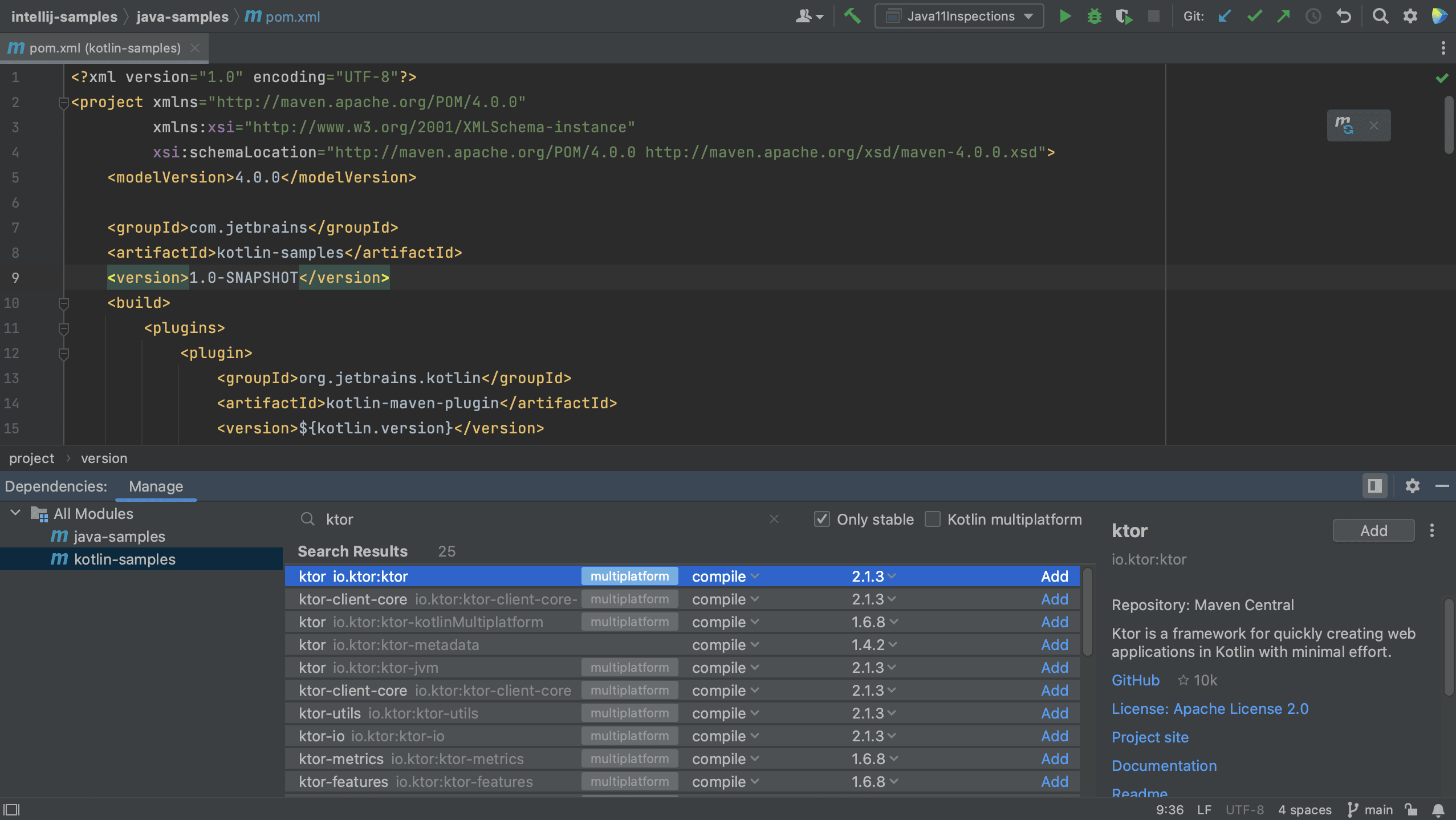
Finally, let’s also add a new dependency to the Kotlin module. Let’s switch to the Kotlin module and open the pom.xml for this module. Open the Dependencies Tool Window and search for Ktor.
Notice that some dependencies are marked as Multiplatform.
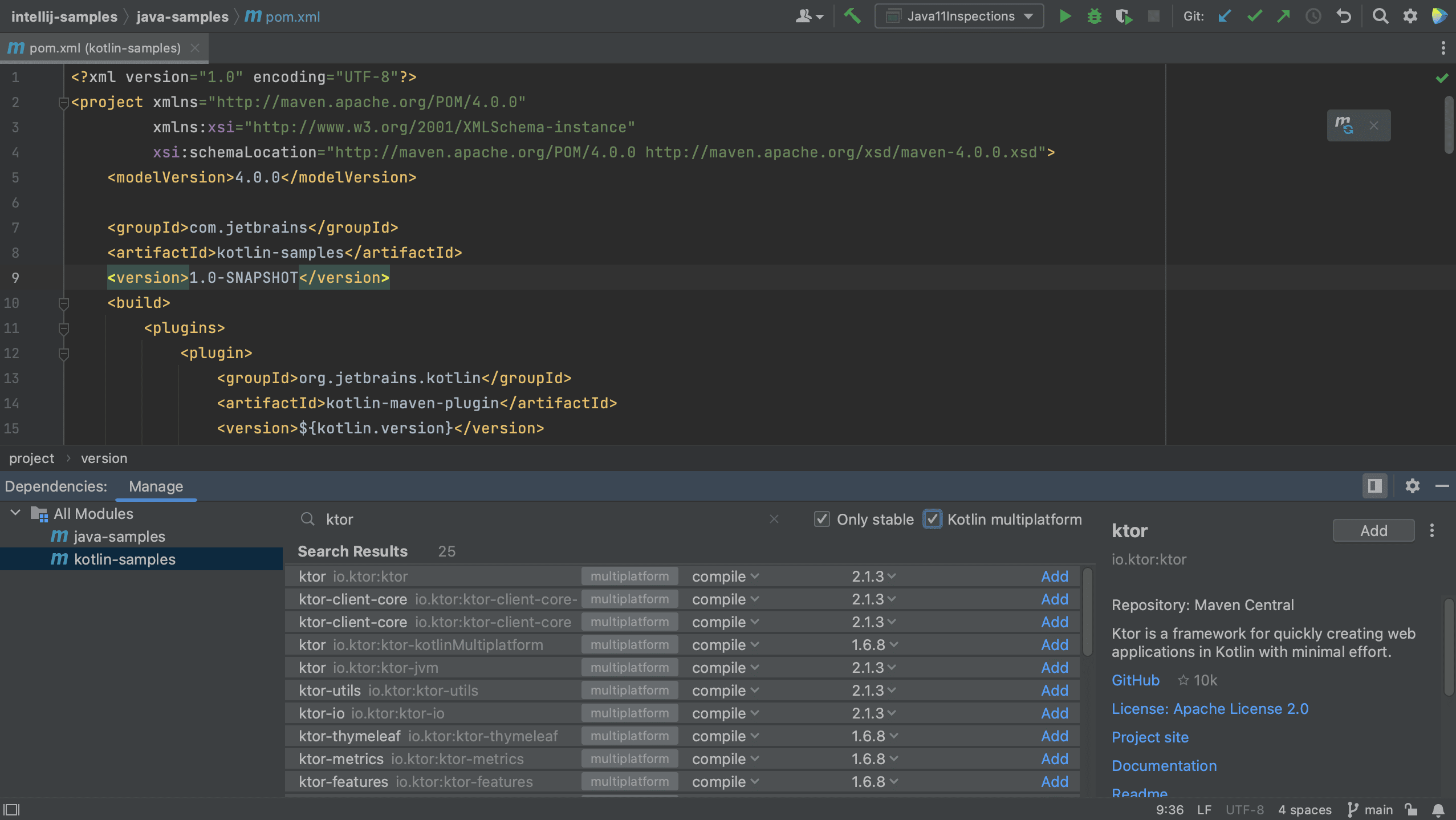
If we want to see only Kotlin multiplatform dependencies, we can select the Kotlin multiplatform checkbox, as shown below.
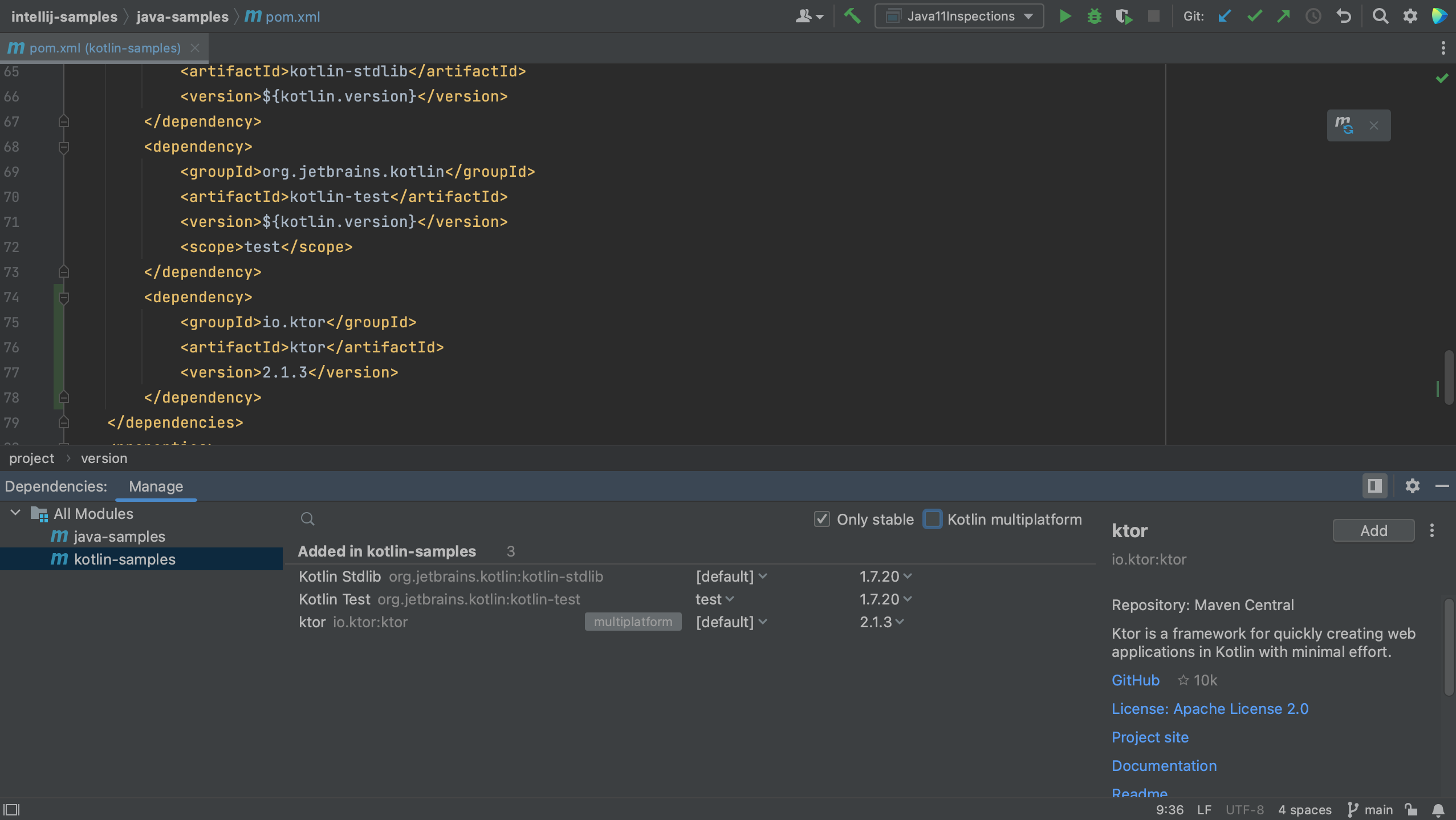
When we click Add to the right of the Ktor dependency, we see that Ktor is added to the list of dependencies and to the pom.xml for the Kotlin module.
Upgrade dependencies
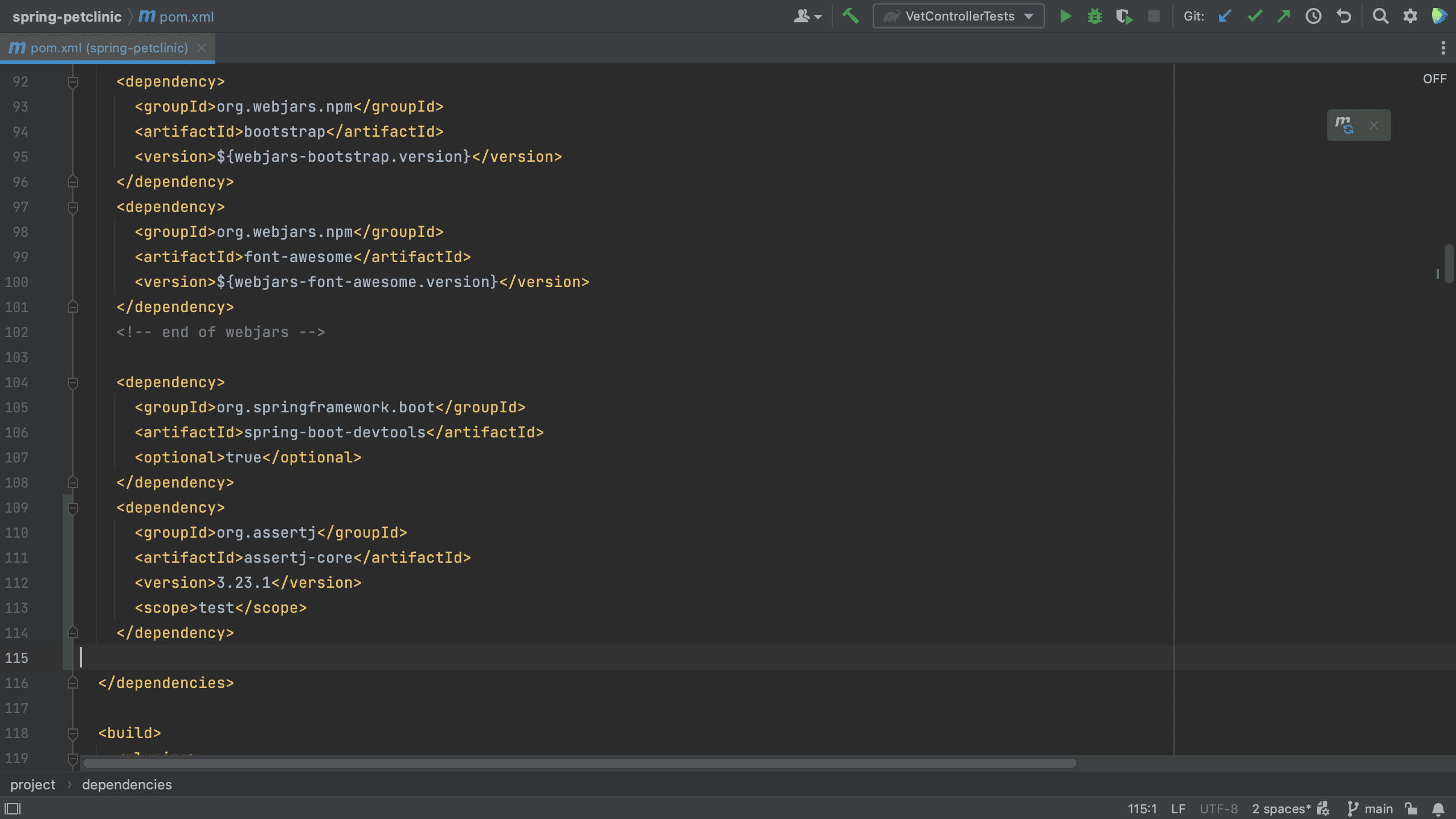
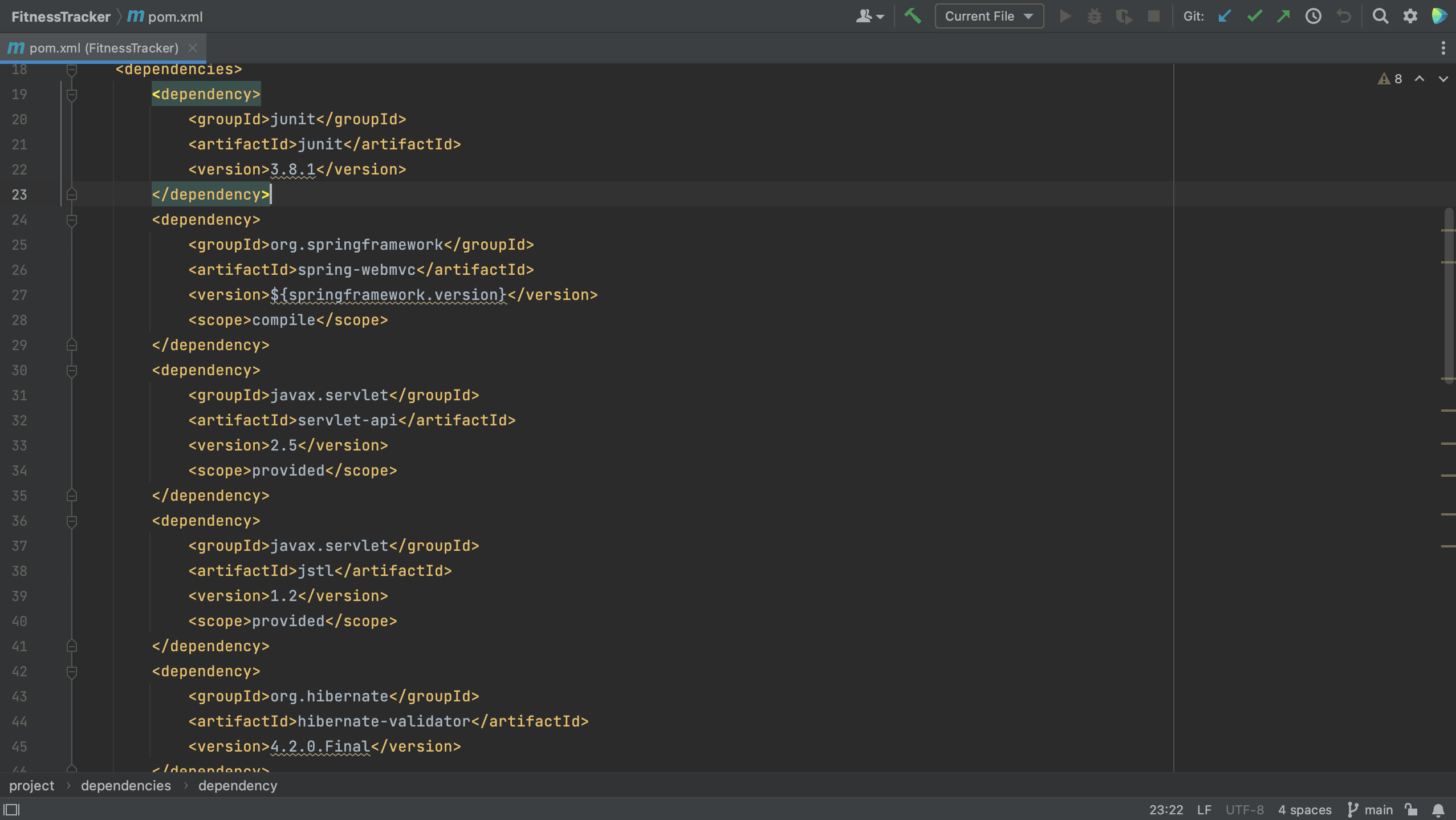
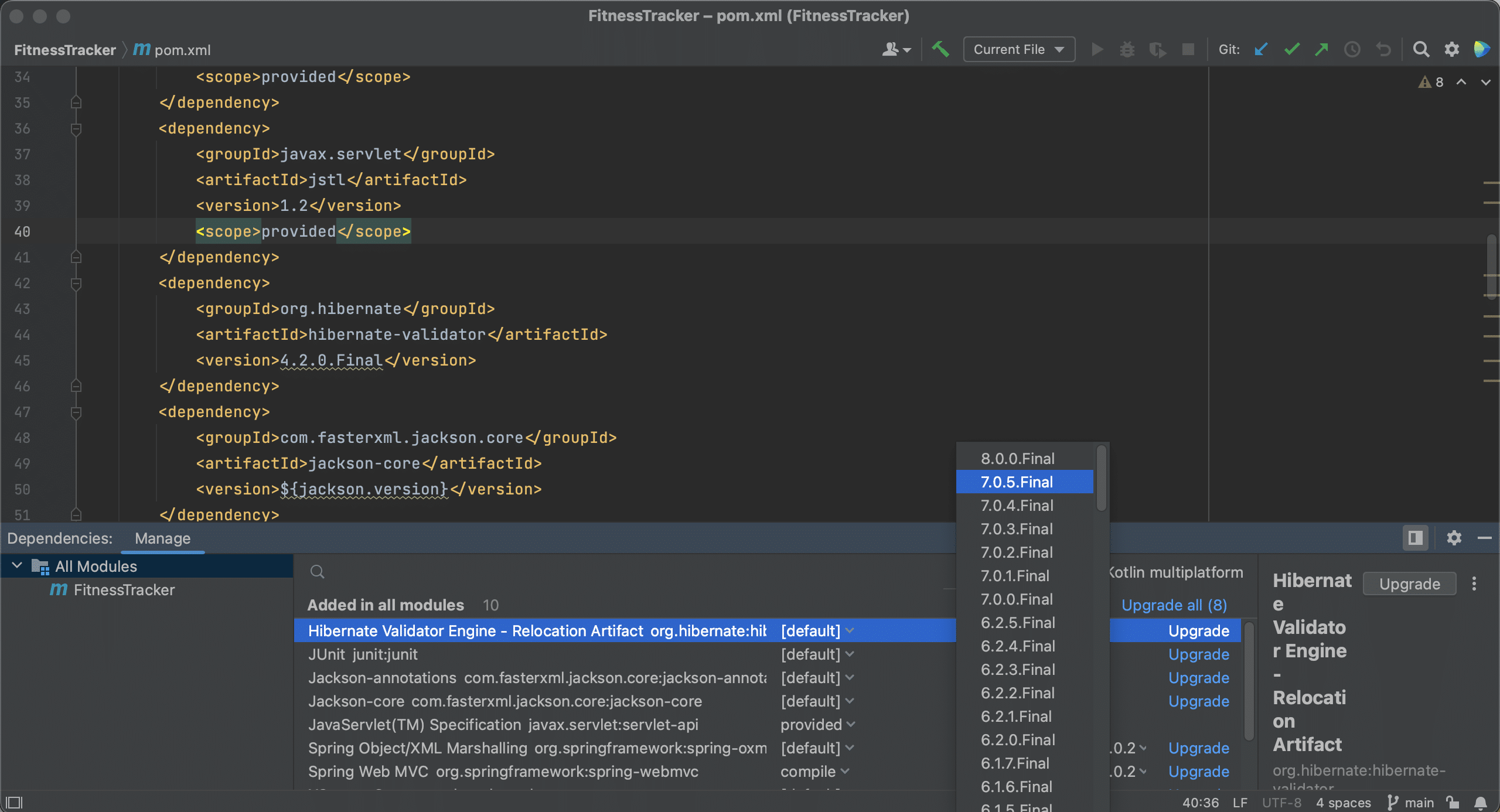
We will also need to keep our dependencies up to date. To show you how IntelliJ IDEA can help, we are using this extremely outdated project as an example. In the pom.xml below, we see that several dependencies are marked with squiggly lines underneath them.
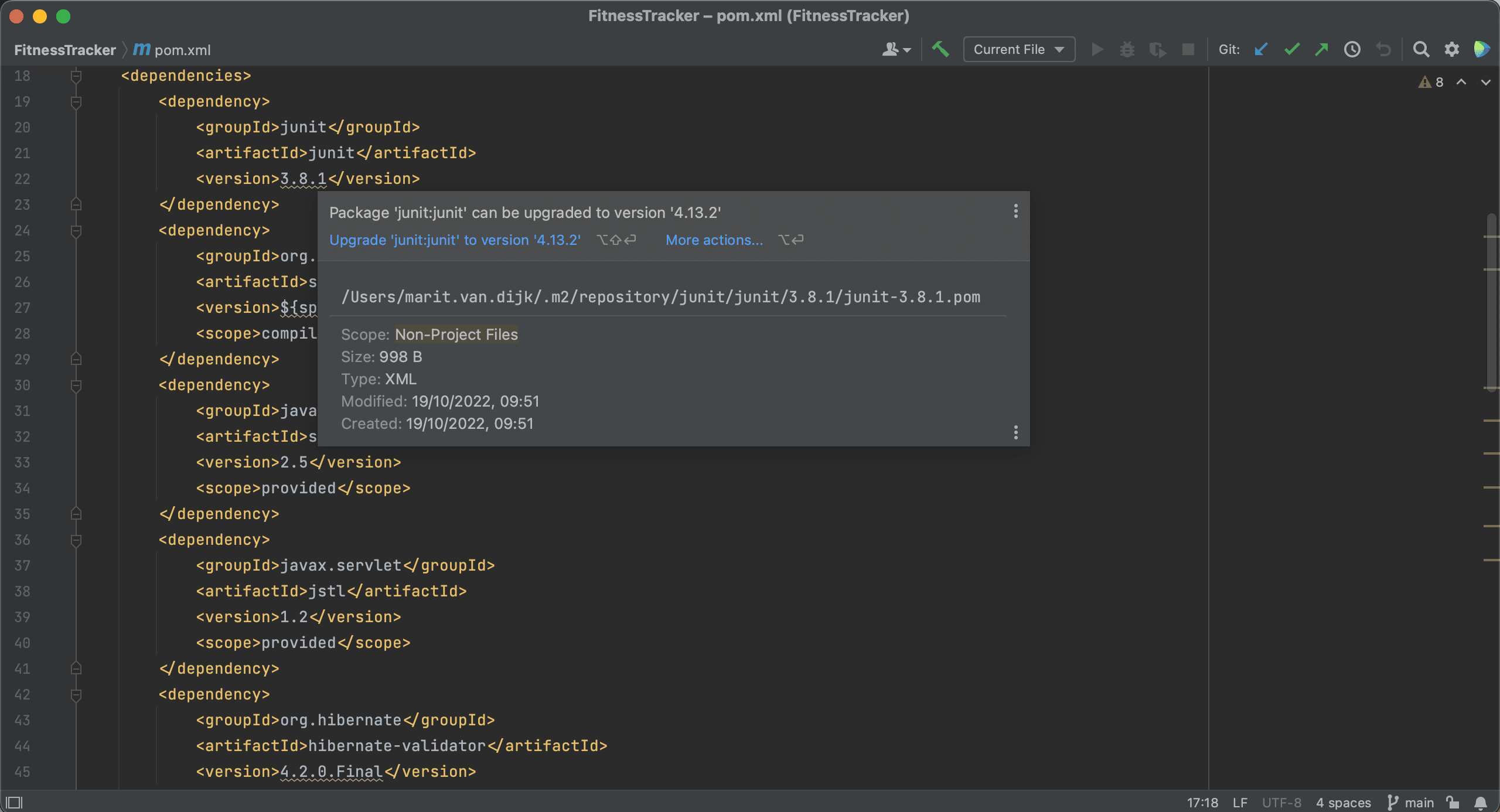
IntelliJ IDEA will show the suggestion to upgrade when we hover over the dependency, and we can click the suggestion to upgrade the dependencies.
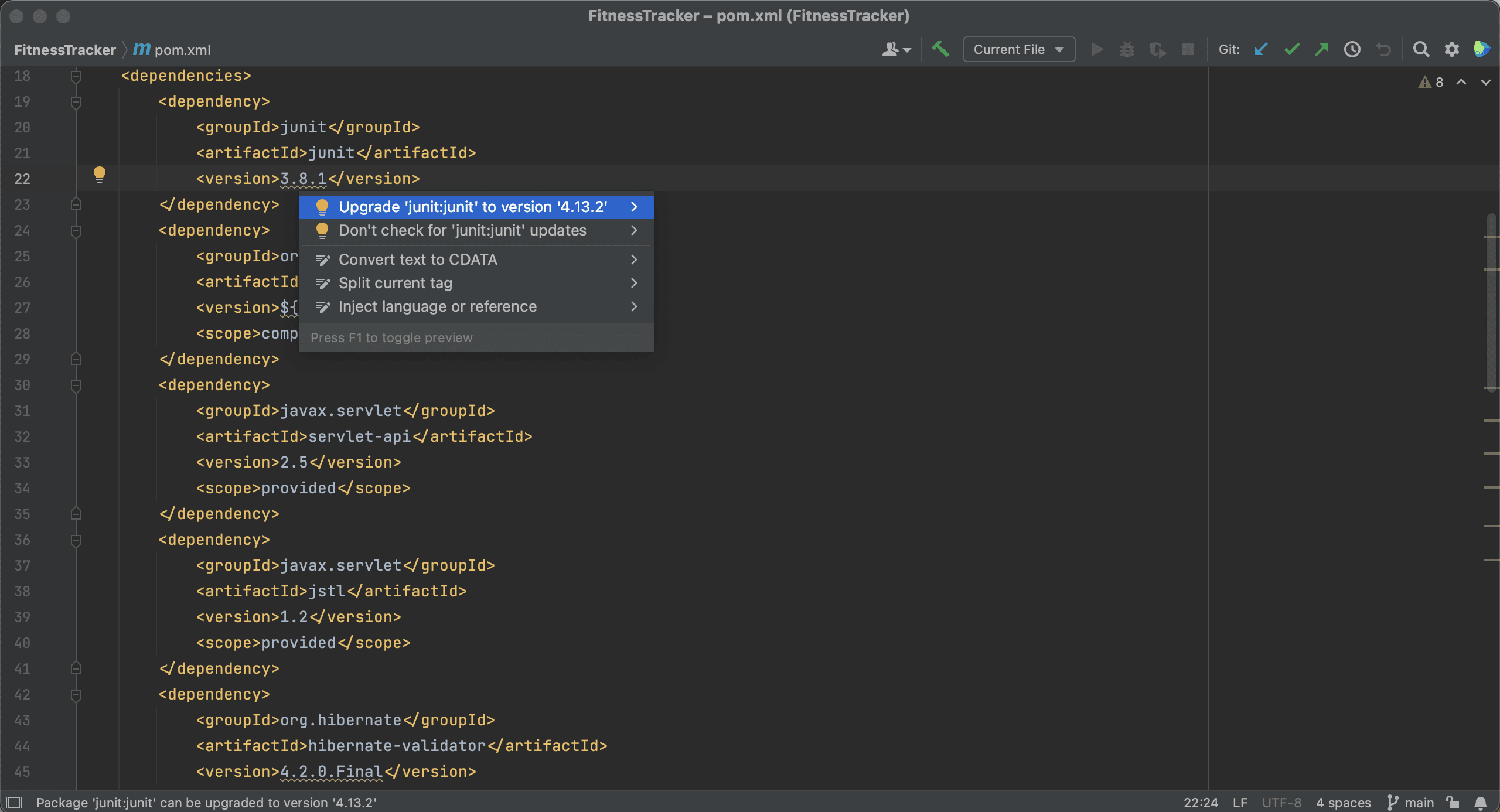
Alternatively, we can use Context Actions ⌥⏎ (on macOS) or Alt+Enter (on Windows & Linux) to upgrade these dependencies.
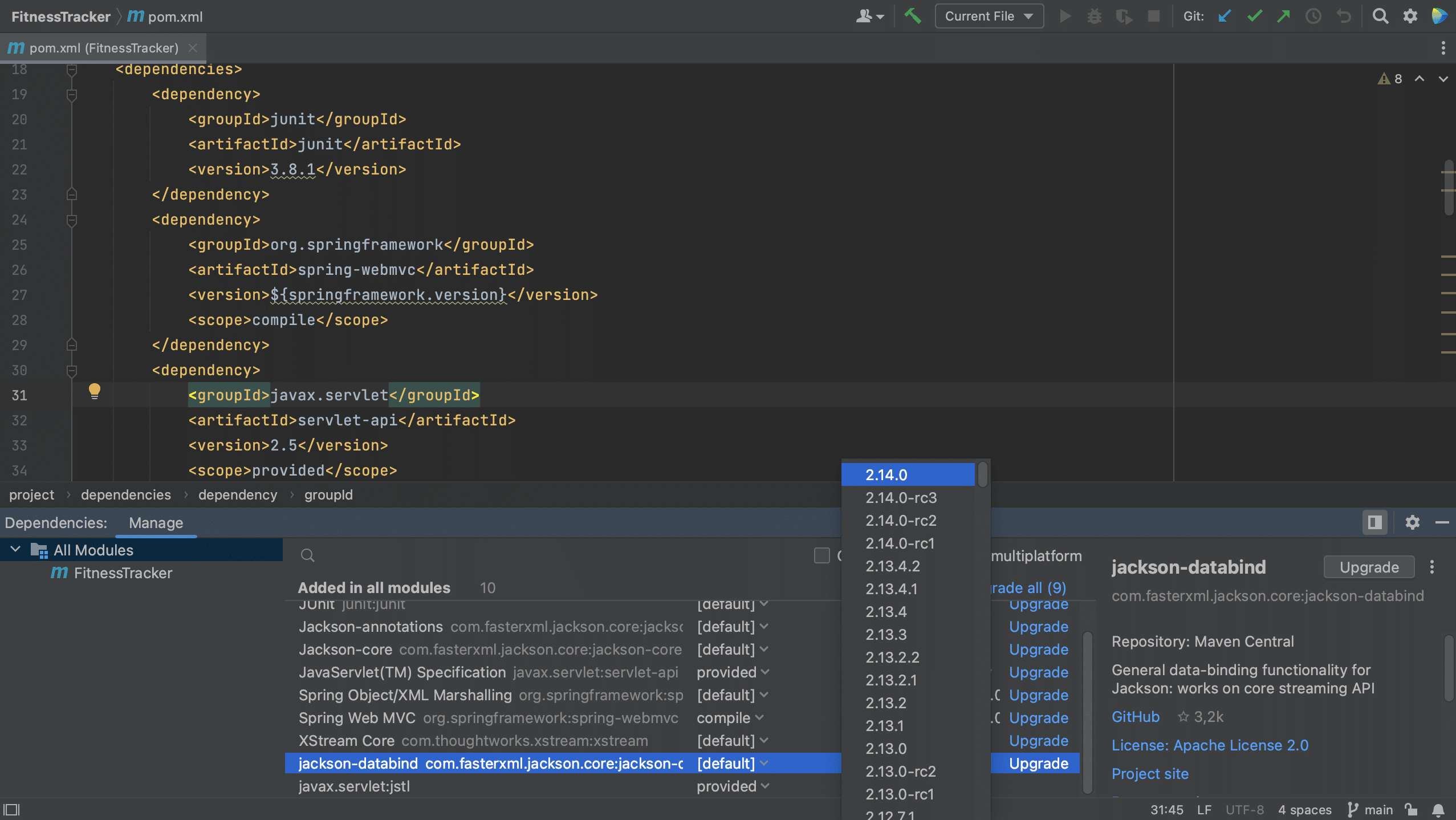
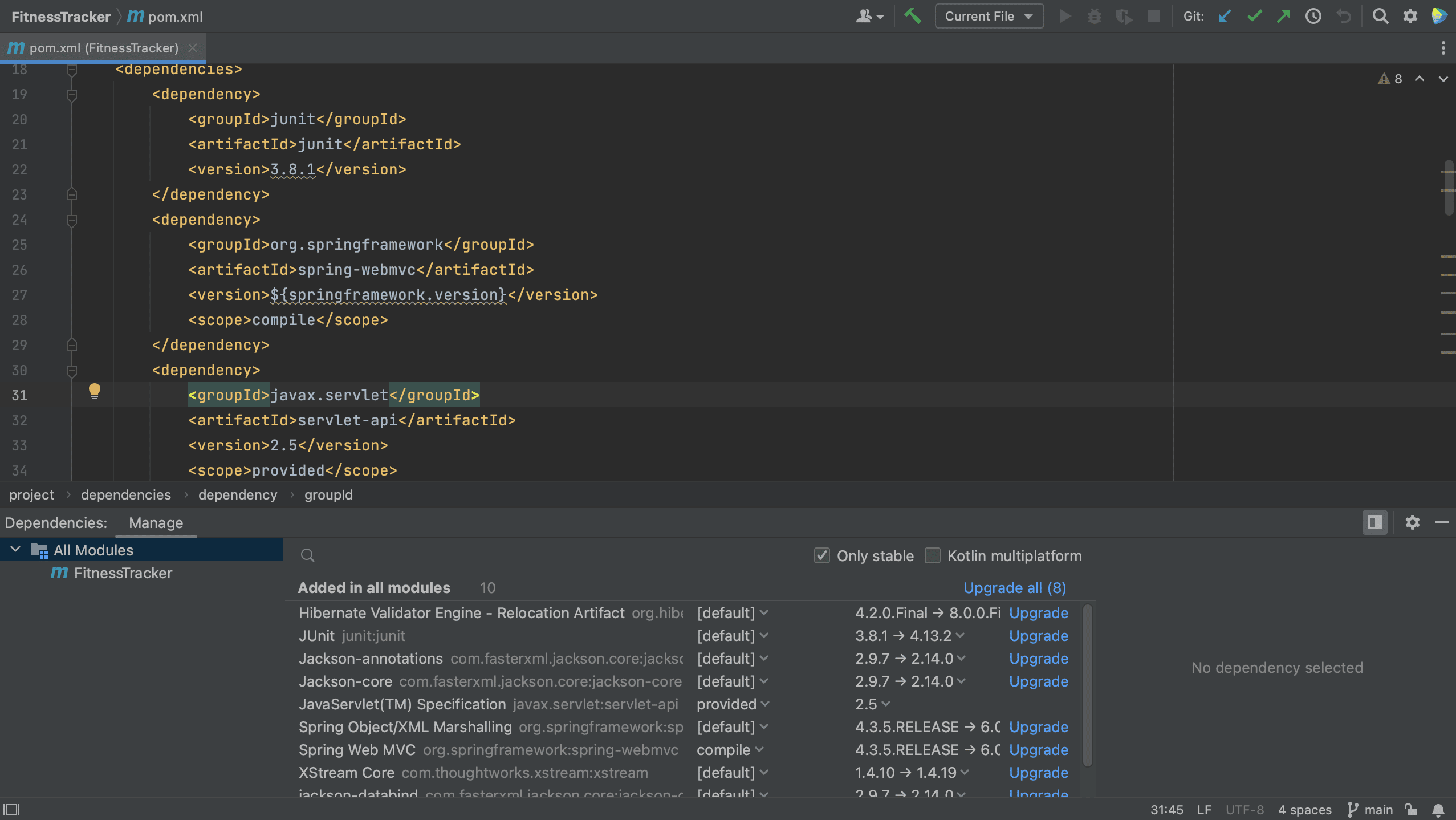
We can also upgrade our dependencies using the Dependencies tool window. The Dependencies tool window will tell us if there’s a newer version of a dependency, as we can see here.
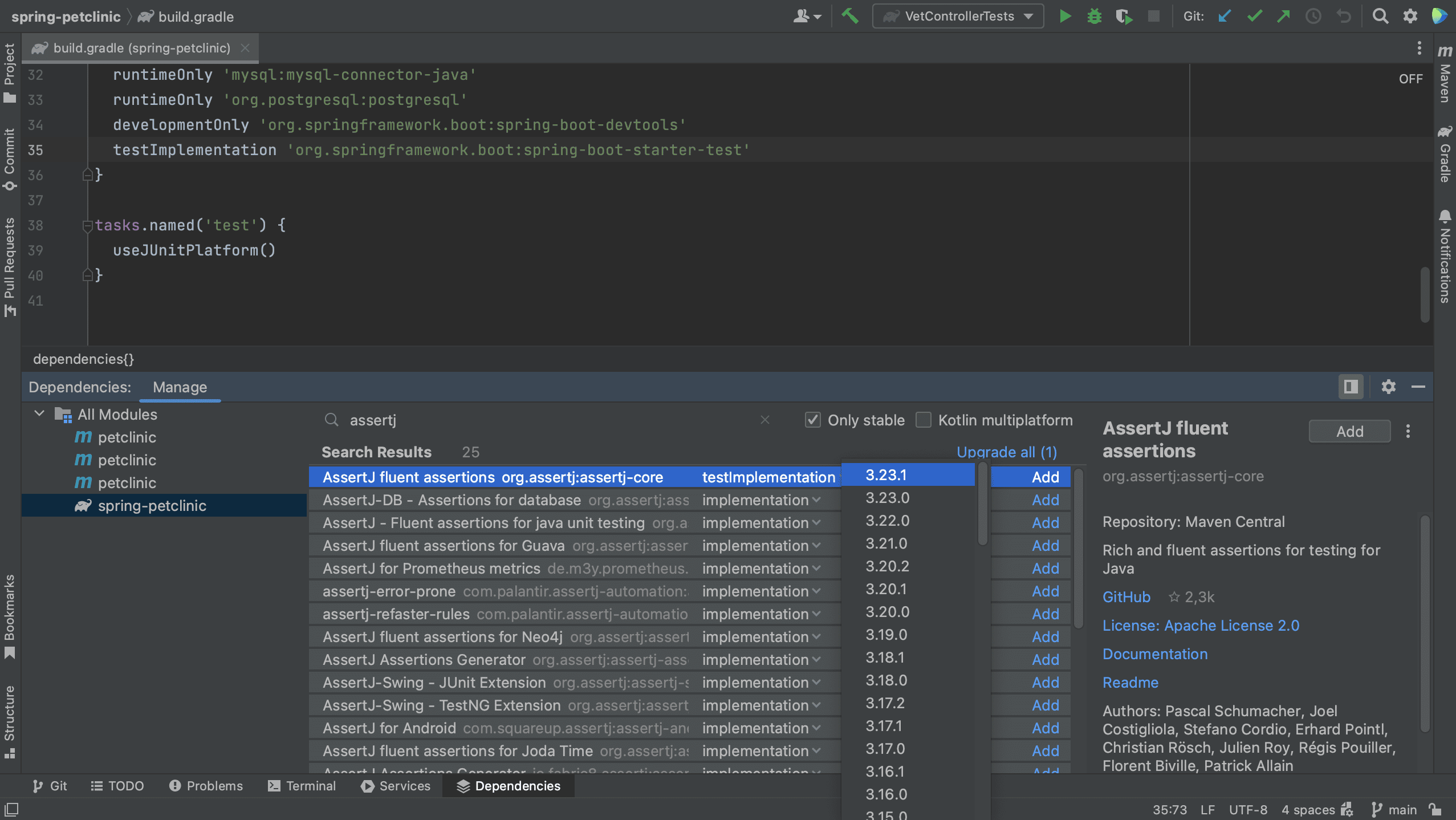
We can choose the version to upgrade to by clicking on the version number in the list. Note that we don’t have to use the latest version.
We can also automatically upgrade a dependency to the latest version by clicking Upgrade for that particular dependency.
Or, we can even upgrade all our dependencies at once, by clicking the Upgrade all link.
Remove dependencies
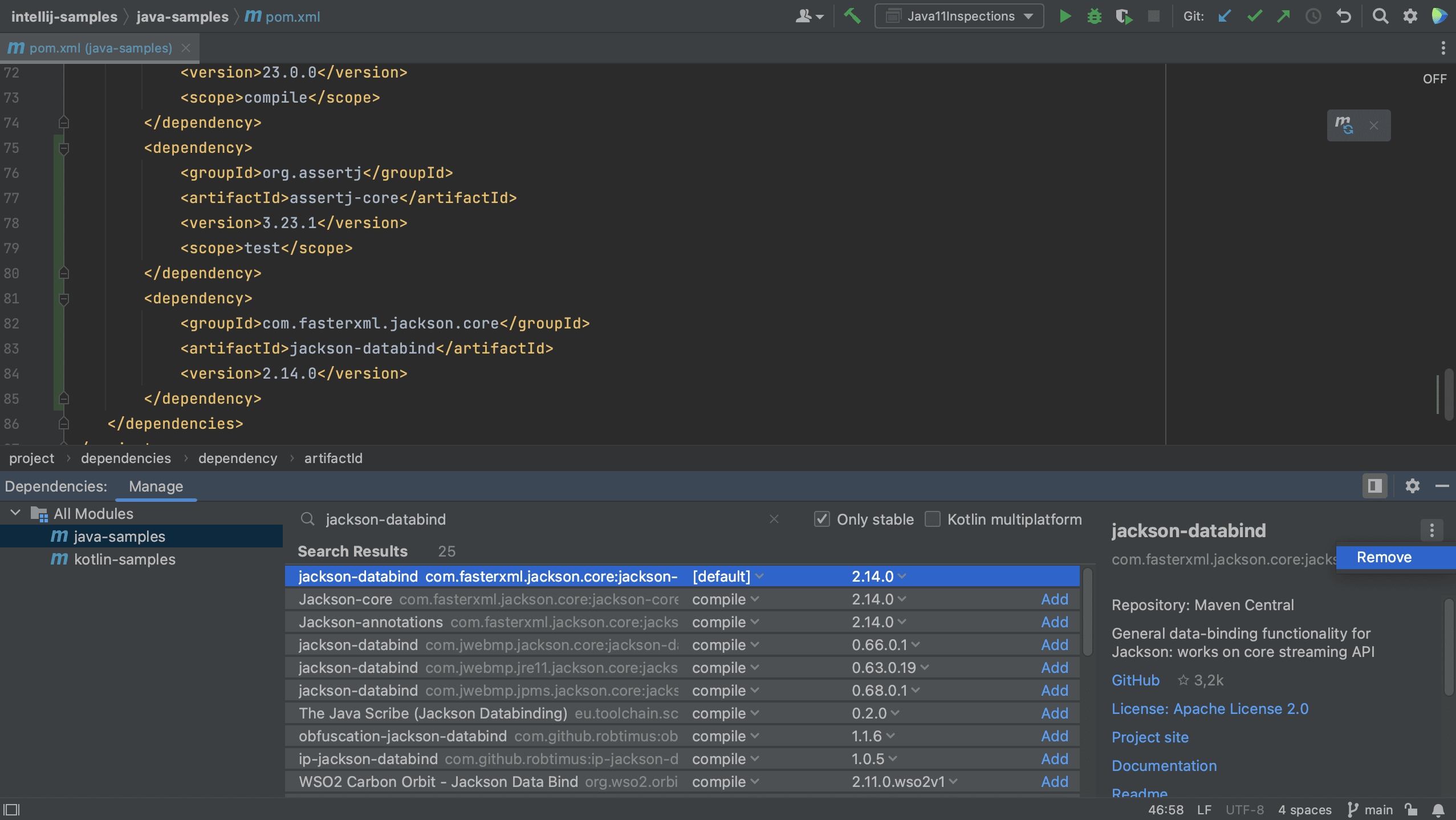
Finally, we can remove dependencies we no longer need. In the Dependencies tool window, let’s remove jackson-databind from the Java module. We select the dependency we want to remove (jackson-databind) and in the Dependency details pane on the right, click the More button (three dots) and select Remove.
We will see that the dependency is removed from the pom.xml and the dependency list. To remove a dependency from the whole project, select All Modules on the left.
Summary and Shortcuts
Now we know the different ways in which we can view our project’s dependencies in IntelliJ IDEA, and the different focus for each view.
IntelliJ IDEA Shortcuts Used
Here are the IntelliJ IDEA shortcuts that we used.
Used to determine whether a user is included in an A / B or Multivariate test.
18 months
_ga
ID used to identify users
2 years
_gali
Used by Google Analytics to determine which links on a page are being clicked
30 seconds
_ga_
ID used to identify users
2 years
_gid
ID used to identify users for 24 hours after last activity
24 hours
_gat
Used to monitor number of Google Analytics server requests when using Google Tag Manager
1 minute
_gac_
Contains information related to marketing campaigns of the user. These are shared with Google AdWords / Google Ads when the Google Ads and Google Analytics accounts are linked together.
90 days
__utma
ID used to identify users and sessions
2 years after last activity
__utmt
Used to monitor number of Google Analytics server requests
10 minutes
__utmb
Used to distinguish new sessions and visits. This cookie is set when the GA.js javascript library is loaded and there is no existing __utmb cookie. The cookie is updated every time data is sent to the Google Analytics server.
30 minutes after last activity
__utmc
Used only with old Urchin versions of Google Analytics and not with GA.js. Was used to distinguish between new sessions and visits at the end of a session.
End of session (browser)
__utmz
Contains information about the traffic source or campaign that directed user to the website. The cookie is set when the GA.js javascript is loaded and updated when data is sent to the Google Anaytics server
6 months after last activity
__utmv
Contains custom information set by the web developer via the _setCustomVar method in Google Analytics. This cookie is updated every time new data is sent to the Google Analytics server.